本文是翻译于AppCoda社区,如有版权问题,请告知,会配合处理
原文时间:2018-06-15
就像 Apple 为她的开发者社区做了很多事情一样,另一家不遗余力的为她的开发者创造出色工具和服务的公司就是 Google 。最近几年, Google 已经发布和改进了它的多个服务,以便给 iOS 和 Android 开发者更多的功能,比如 Google Cloud 、Firebase 、 TensorFlow 等等。
今年,在 Google I/O 2018 上, Google 向她的开发者们发布了一款叫做 ML Kit 的全新工具包。 Google 一直处于人工智能领域的最前沿,并且通过让开发者使用 ML Kit 模型,Google 已经赋能给了开发者。

使用 ML Kit ,你需要很少的代码就能够执行各种机器学习的任务。 CoreML 和 ML Kit 一个最主要的区别就是:使用 CoreML ,你必须添加自己的模型,但使用 ML Kit ,你可以依靠 Google 为你提供的模型或者使用你自己的模型。在本教程中,我们将依靠使用 Google 的模型,因为添加自己的 ML 模型需要 TensorFlow 和 非常了解 TensorFlow 。
编辑提示:随着 WWDC 18 的发布,你现在可以在 Xcode 10 的 Playgrounds 中使用 Create ML 去创建你自己 ML 模型
另一个不同点就是如果你的模型太大了,你可以把你的 ML 模型放到 Firebase 中,然后让你的 app 去调用服务器。在 CoreML 中,你只能在设备中跑机器学习模型。这有一个 ML Kit 的能力列表:
- 扫描条形码
- 脸部检测
- 图片标签
- 文本识别
- 地表识别
- 智能回复(还没发布,但快了)
在本教程中,我将向你展示如何用 Firebase 创建一个项目,使用 Cocoapods 去下载依赖包和集成 ML Kit 到你的 app !我们开始!
创建一个 Firebase 项目
第一步就是去 Firebase 控制台。在这儿你将会被提示去登录你的 Google 账号。登录之后,你会看到一个欢迎页面,就像这样。
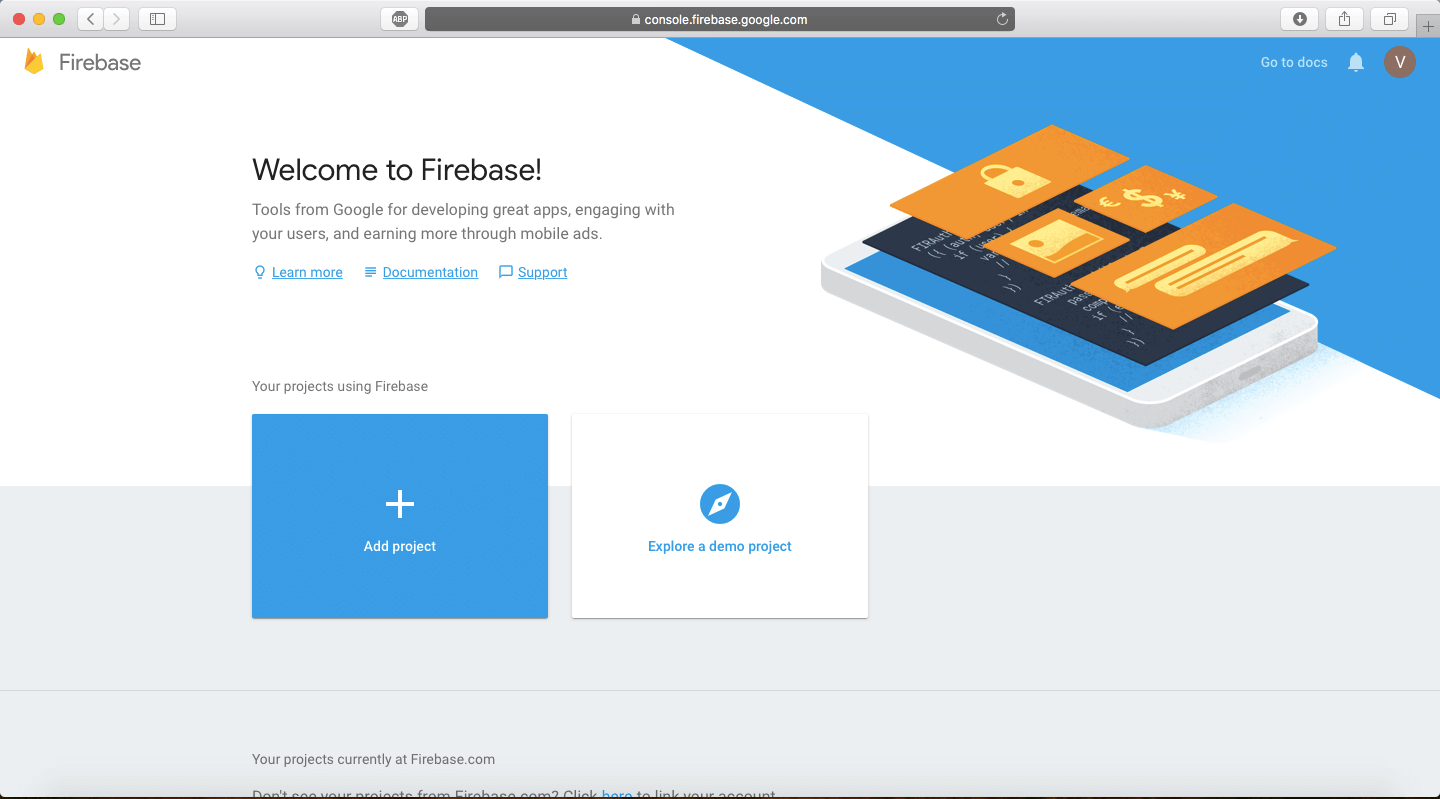
点击 Add Project 按钮,然后给你的项目命名,我们这个项目就叫 ML Kit Introduction 。保留 Project ID 并根据需求去修改 国家/地区,然后点击 Create Project 按钮,这可能会还一点时间。
注意: 在到达限额之前你只能创建一定数量的 Firebase 项目,谨慎创建你的项目。
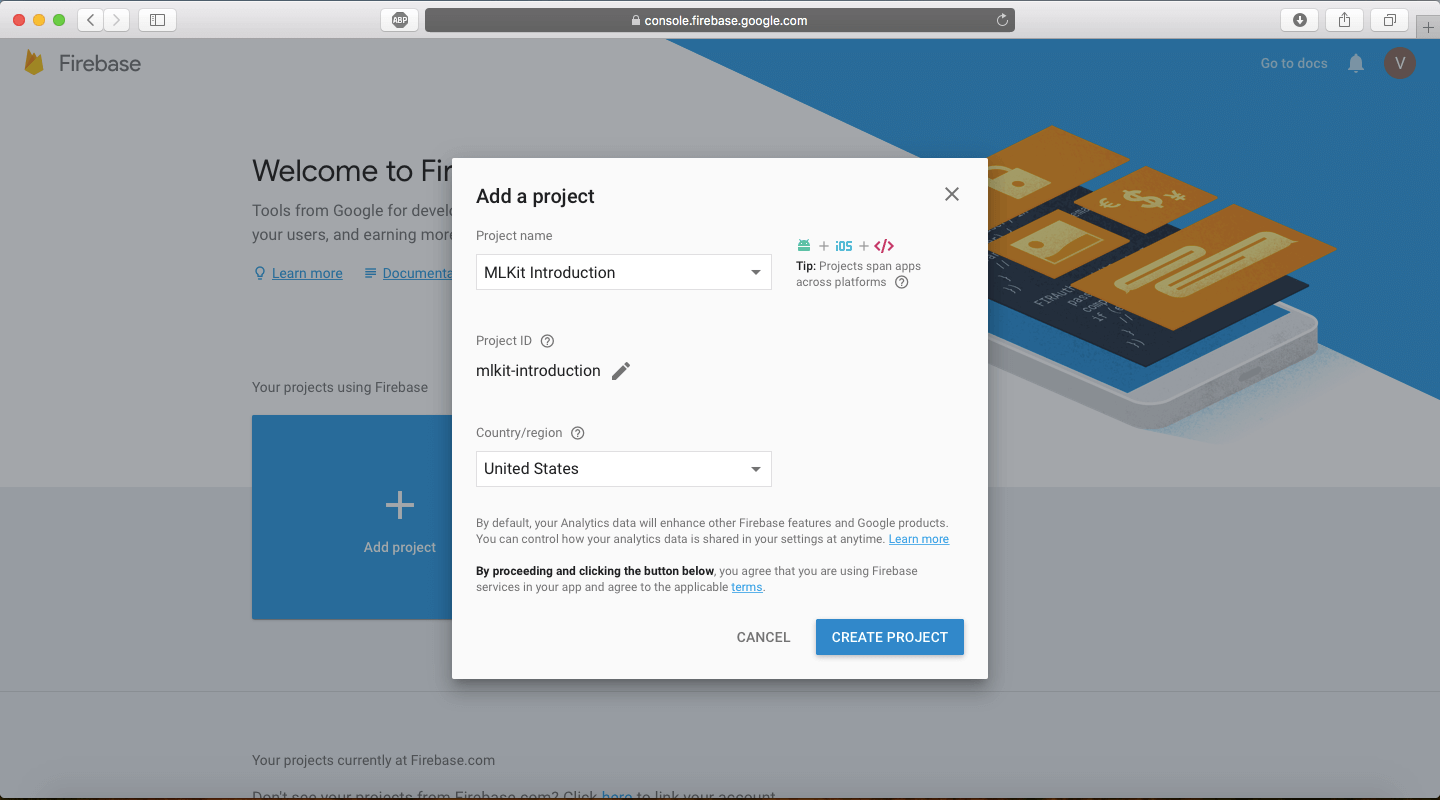
当所有的事情都搞定了之后,你会看到这样的界面!
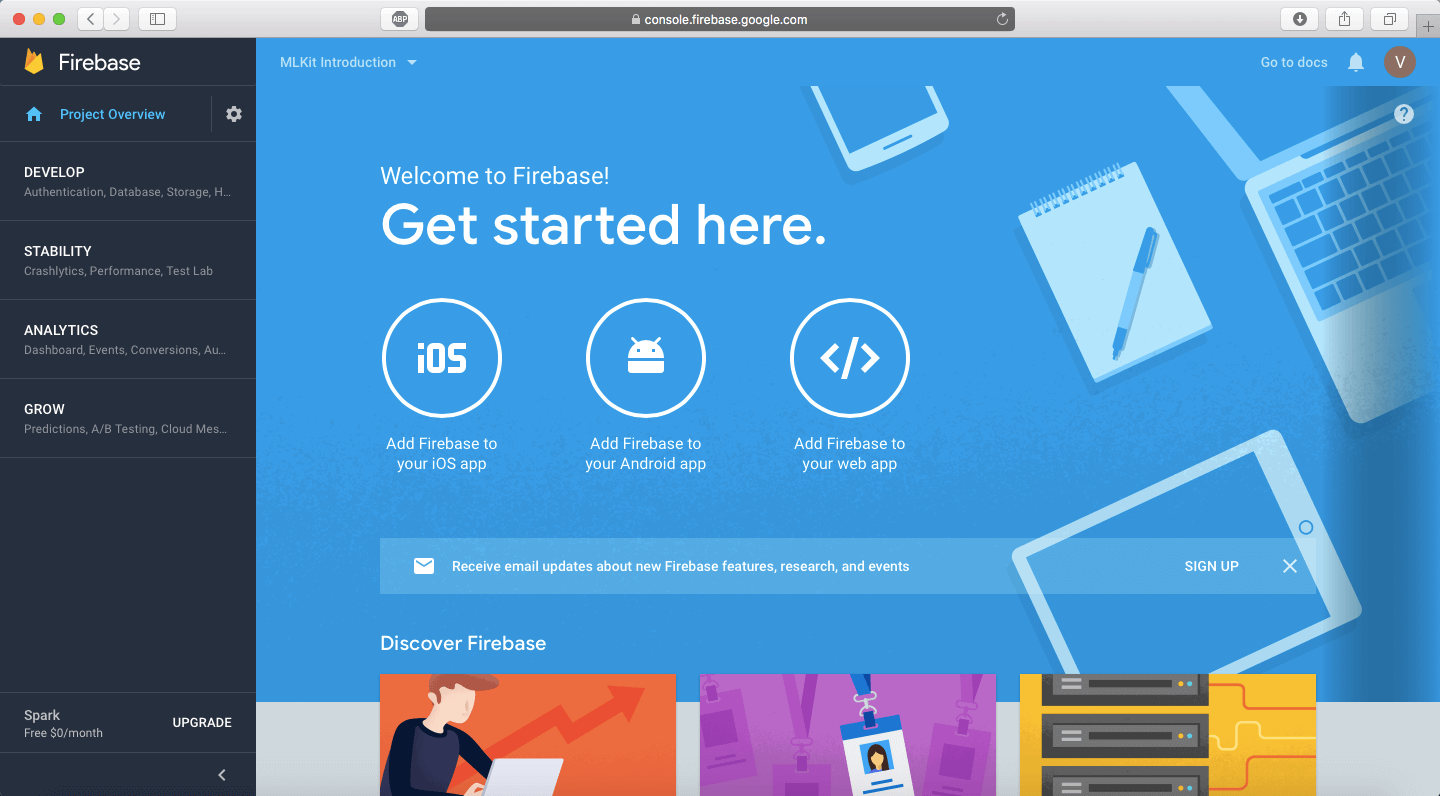
这是你的项目概览页面,并且你可以从这个控制台中操作各种各样的 Firebase 控件。恭喜!你刚刚创建了你第一个 Firebase 项目!保持这个项目不变,我们将切换到第二个来看看 iOS 项目。在这里下载启动项目.
快速浏览启动项目
打开启动项目,你会看到大部分的 UI 都已经为你设计好了。构建并运行 app ,你会看到一个 UITableView ,可以根据 ML Kit 的选项去到不同的页面。
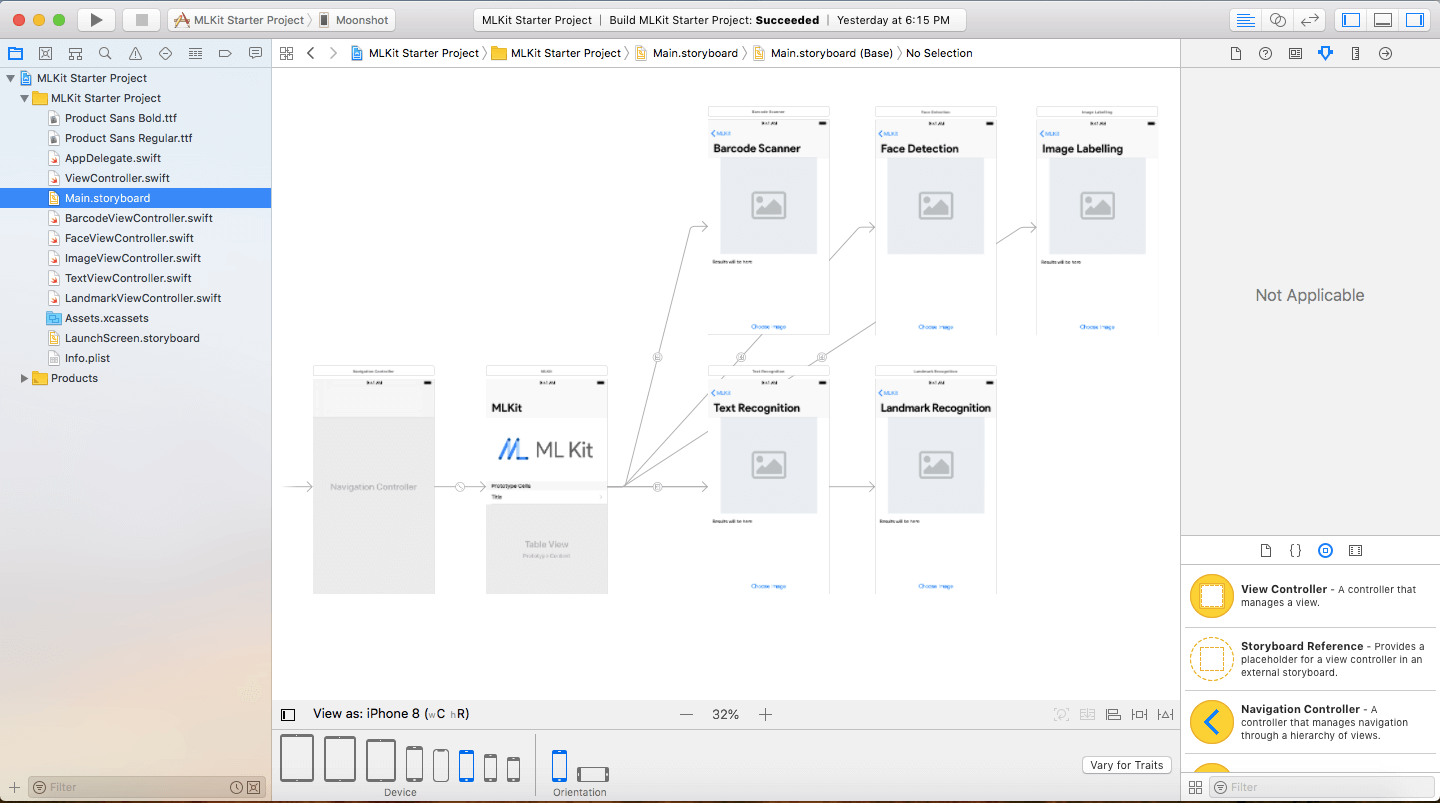
如果你点击了 Choose Image 按钮, UIImagePickerView 会弹出,选择一张图片就会替换空的占位图。然而,如果没有反应,是因为我们集成了 ML Kit 并且 ML Kit 正在这张图片上执行它的机器学习任务。
将 Firebase 链接到 app
回到 Firebase 项目的控制台,点击 「Add Firebase to your iOS App」按钮。
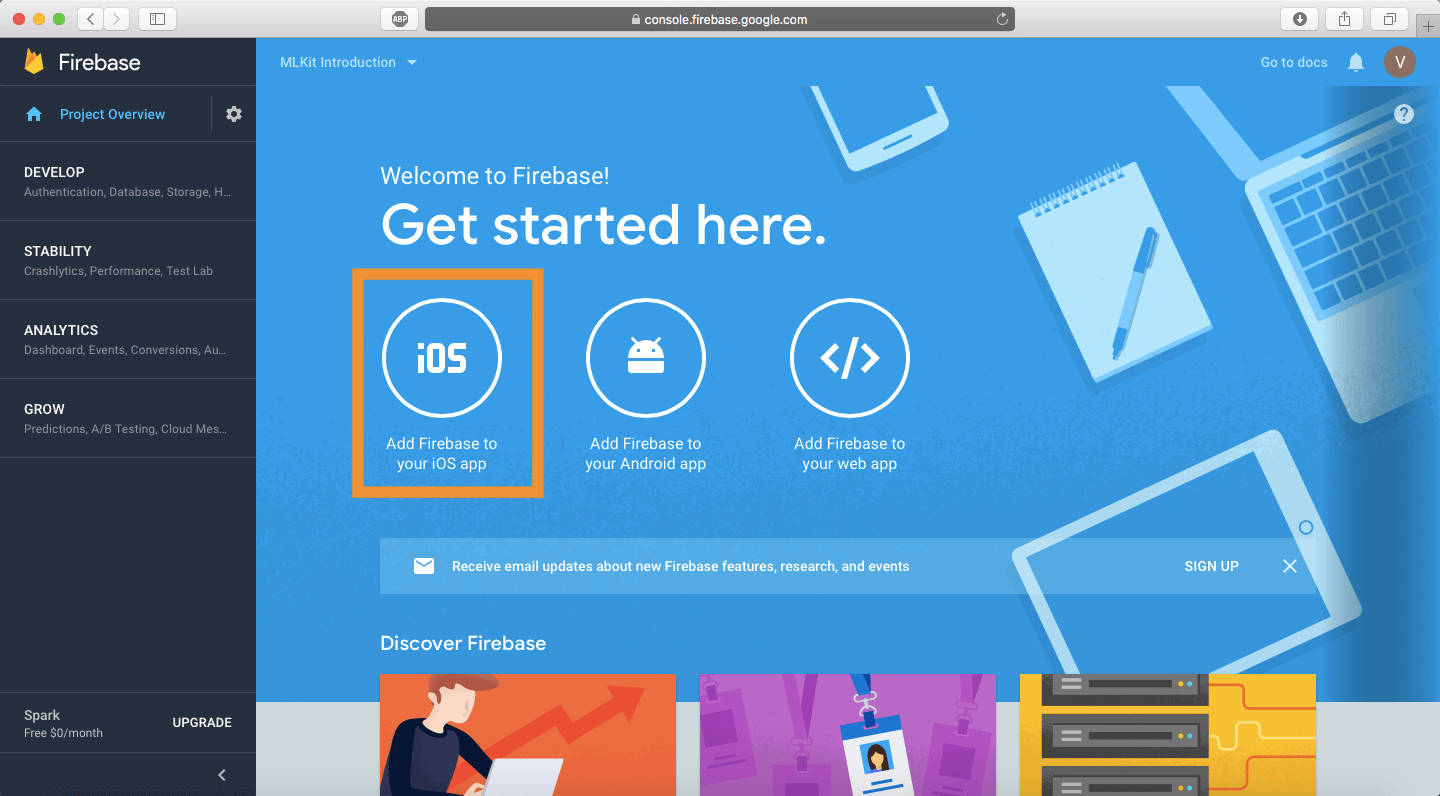
你会收到一个弹框,是关于如何链接 Firebase 的说明。首先要做的就是去链接你输入的 Bundle ID 。你可以在 Xcode 项目概览里面 General 标签下找到它。
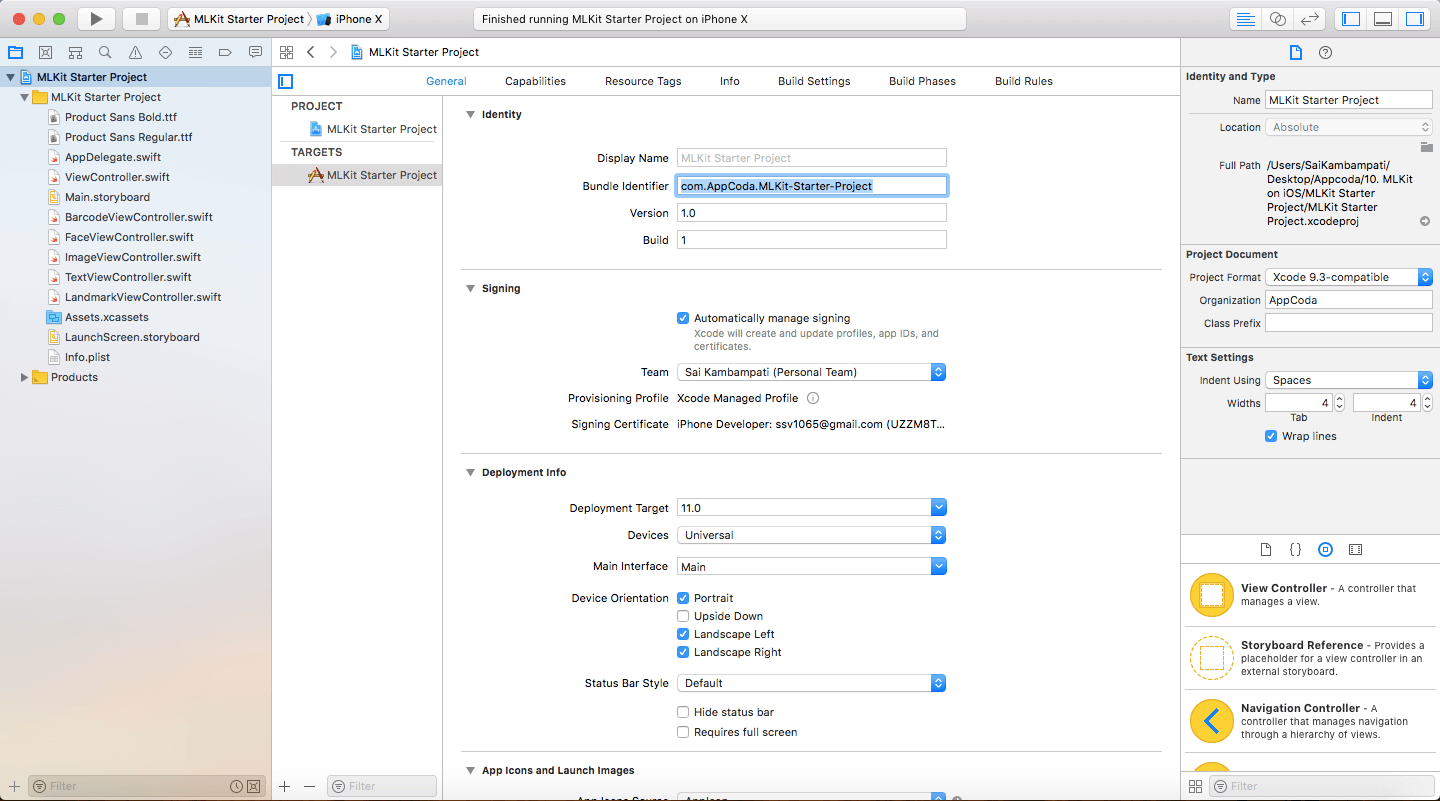
把它输入到输入框中,然后点击名为 Register App 的按钮,你不需要输入任何信息在选项的文本框中,因为这个 app 不会上传到 App Store 。然后你将会进入第二步,这里你会被要求下载一个 GoogleService-Info.plist 文件,这个文件非常重要,将会被添加到你的项目中。点击 Download 按钮去下载这个文件。
将文件拖入到项目中,如 Firebase 网站上所示,确保 Copy items if needed 选项是被选中的,如果所有事情都做好了,就点击 Next 按钮,然后处理第三步。
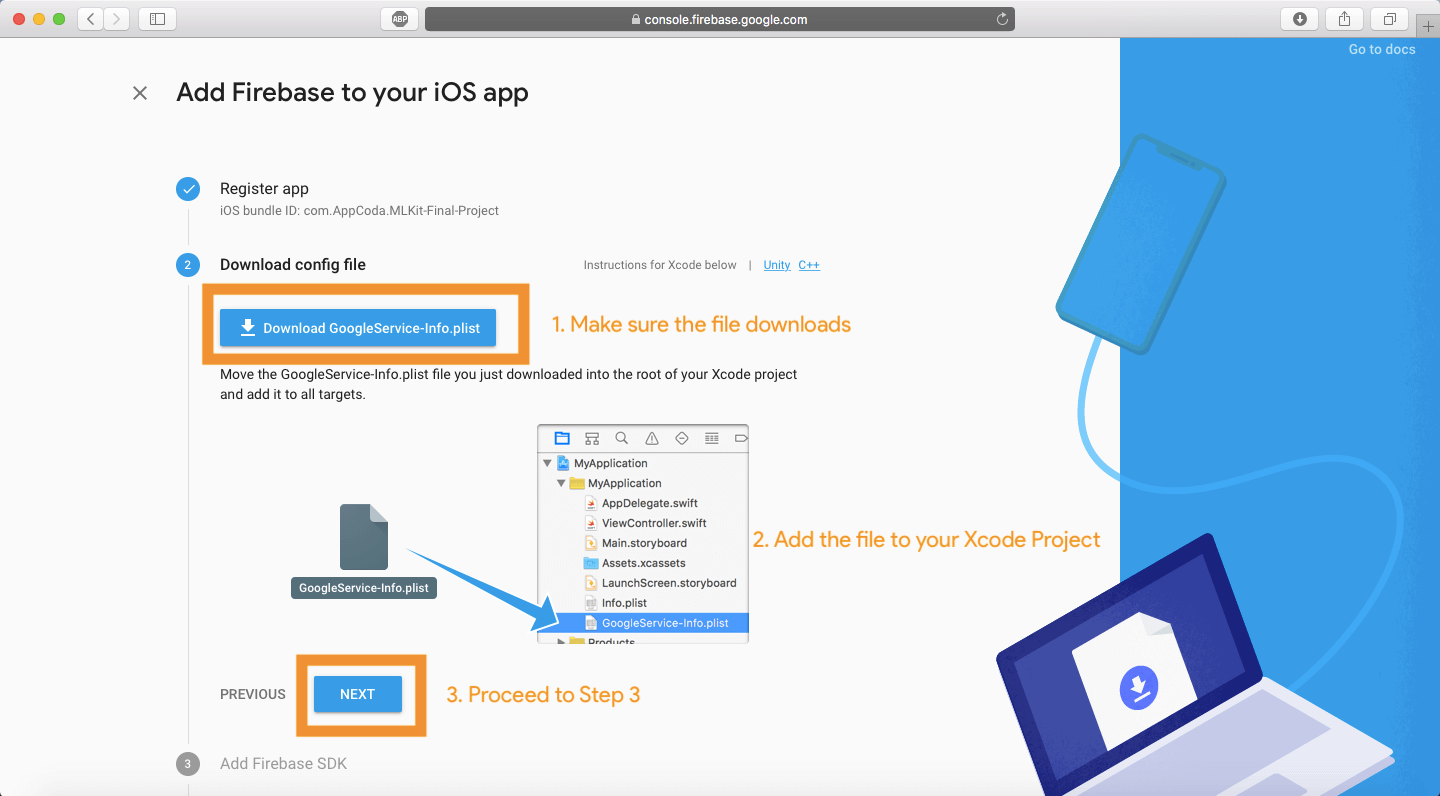
使用 Cocoapods 安装 Firebase 库
下一步将会介绍一下 Cocoapods 的概念。 Cocoapods 对你来说是一个基本方式,可以用一个简单的方法把包导入你的项目中。然后,如果任何细节处理错误,就会导致很多灾难性的后果。首先,关闭 Xcode 的所有窗口并退出。
注意:确保你的设备中已经安装了 Cocoapods 。如果没有的话,这里有个很棒的 Cocoapods 教程可以教你把它安装到你的 Mac 中。
在 Mac 中打开终端,输入以下命令:
cd <你的 Xcode Project 路径>
提示:为了获取你的 Xcode 项目的路径,选中 Xcode 项目文件,按下 CMD+C ,然后,打开终端,输入 cd 并粘贴。
你现在已经在那个目录下了。
创建一个 pod ,这很简单,只需要输入下面的命令:
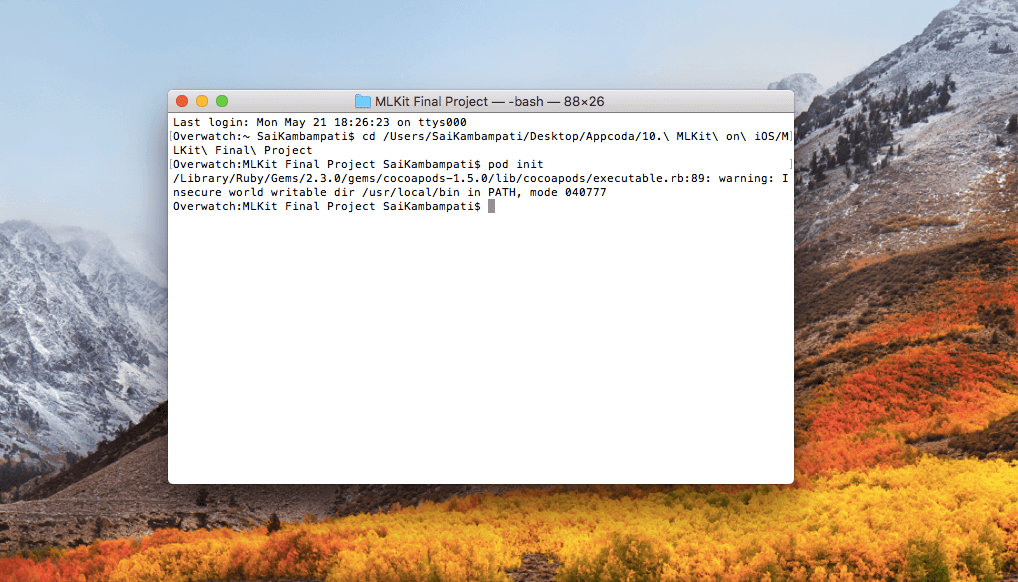
pod init
等一会儿,你的终端看起来应该像这样,只添加了简单的一行。
现在,让我们把我们所需要的包都添加到我们的 Podfile 中,在终端中输入以下命令,然后等到 Xcode 打开:
open -a Xcode podfile
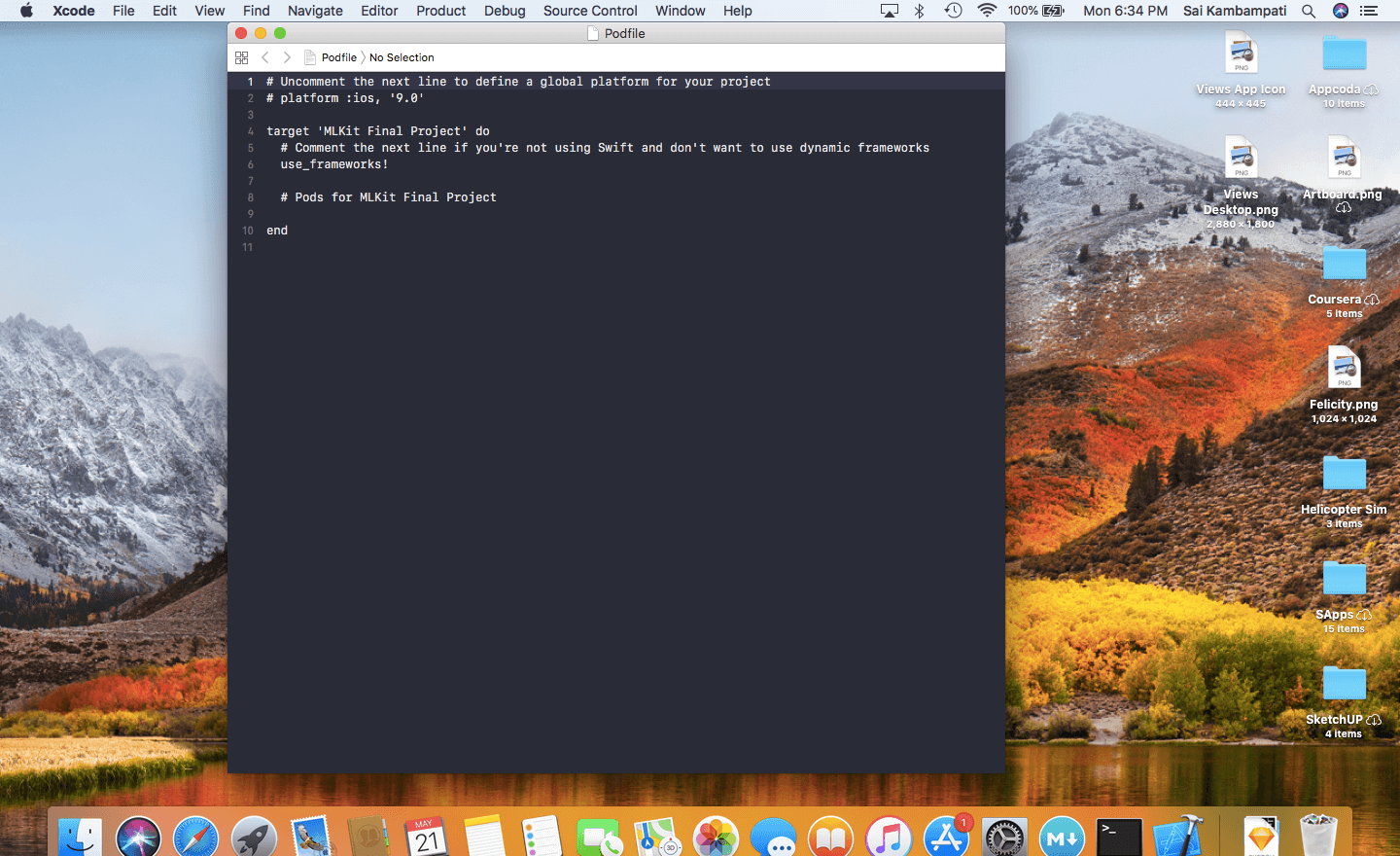
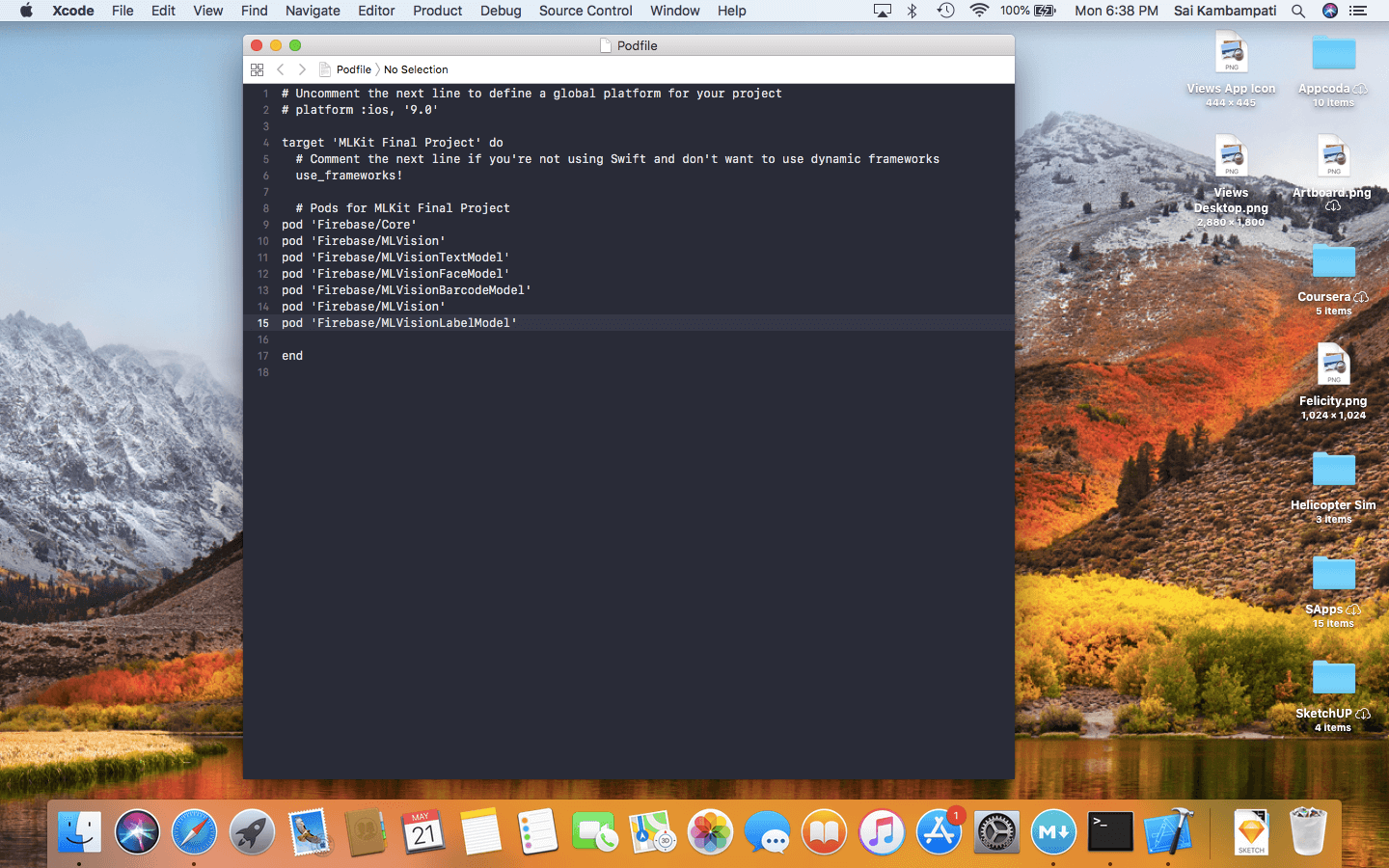
在 # Pods for ML Kit Starter Project 下面,输入以下代码:
pod 'Firebase/Core'
pod 'Firebase/MLVision'
pod 'Firebase/MLVisionTextModel'
pod 'Firebase/MLVisionFaceModel'
pod 'Firebase/MLVisionBarcodeModel'
pod 'Firebase/MLVision'
pod 'Firebase/MLVisionLabelModel'
你的 Podfile 看起来应该像这样。
现在,只剩下一件事情了,回到终端然后输入:
pod install
这将需要几分钟,因此你可以休息一下,与此同时, Xcode 正在下载我们需要用到的包。当所有出完成后,打开 Xcode 项目文件夹,你将会注意到一个的 .xcworkspace 文件。
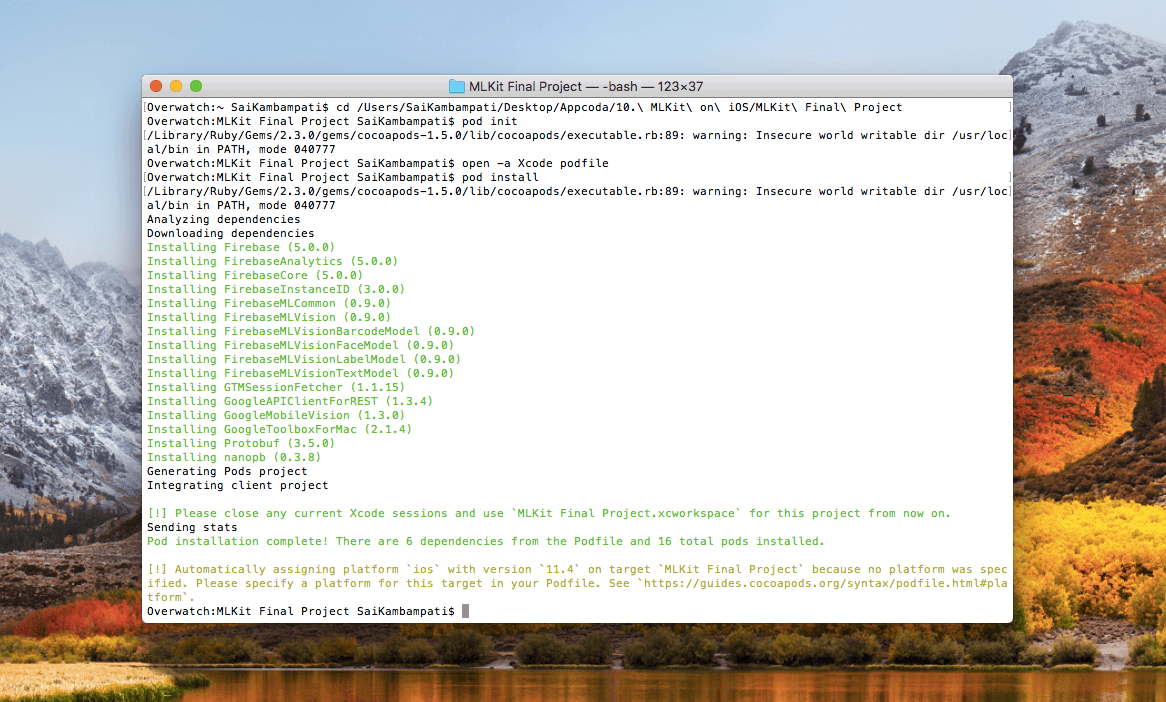
这是大部分开发者都很迷惑的地方:你从此以后不可以再打开 .XCODEPROJ 文件了!如果你在那里进行和编辑内容,那么这两个内容将不会同步,你将不得不重新创建一个新项目。从现在起,你应该一直打开 .xcworkspace 文件。
回到 Firebase 网页,你将会注意到我们已经完成了第三步,点击 NEXT 按钮,进入第四步。
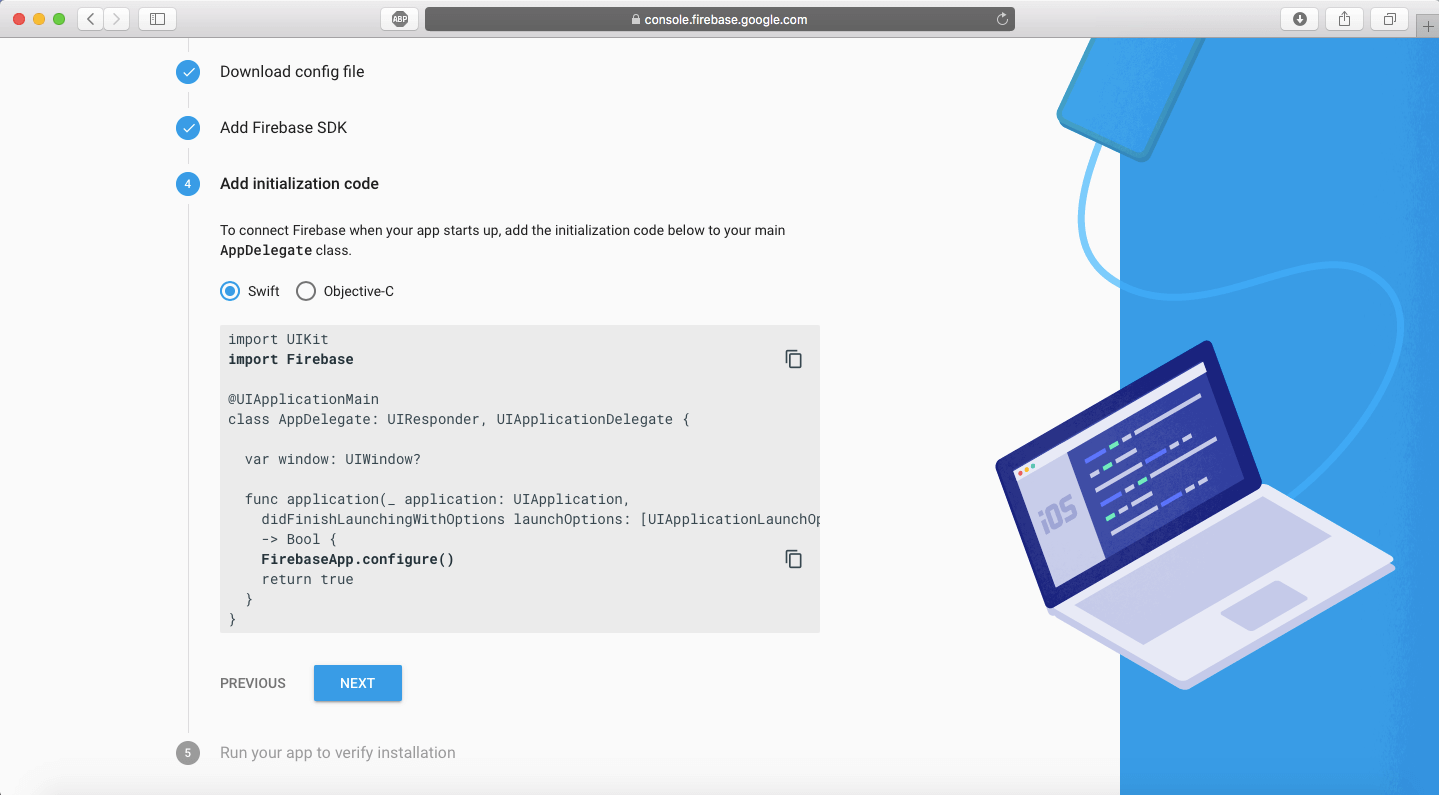
我们现在需要去打开我们的 workspace ,然后在 AppDelegate.swift 文件添加一些代码。打开 .xcworkspace (再次说明,不是 .xcodeproj 文件,我无法重复这是多么重要),然后进入 AppDelegate.swift 文件。
一旦我们进入 AppDelegate.swift ,我们要做的所有事情就是添加两行代码。
import UIKit
import Firebase
@UIApplicationMain
class AppDelegate: UIResponder, UIApplicationDelegate {
var window: UIWindow?
func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplicationLaunchOptionsKey: Any]?) -> Bool {
// 应用启动后重写 FirebaseApp 的自定义配置
FirebaseApp.configure()
return true
}
我们正在做的所有事情就是导入 Firebase 包,然后基于我们之前添加的 GoogleService-Info.plist 文件去配置它。你可以会得到一个 Firebase 模块编译不过的错误,只需要按需 CMD+SHFT+K 去清理一下项目,然后 CMD+B 构建一下。
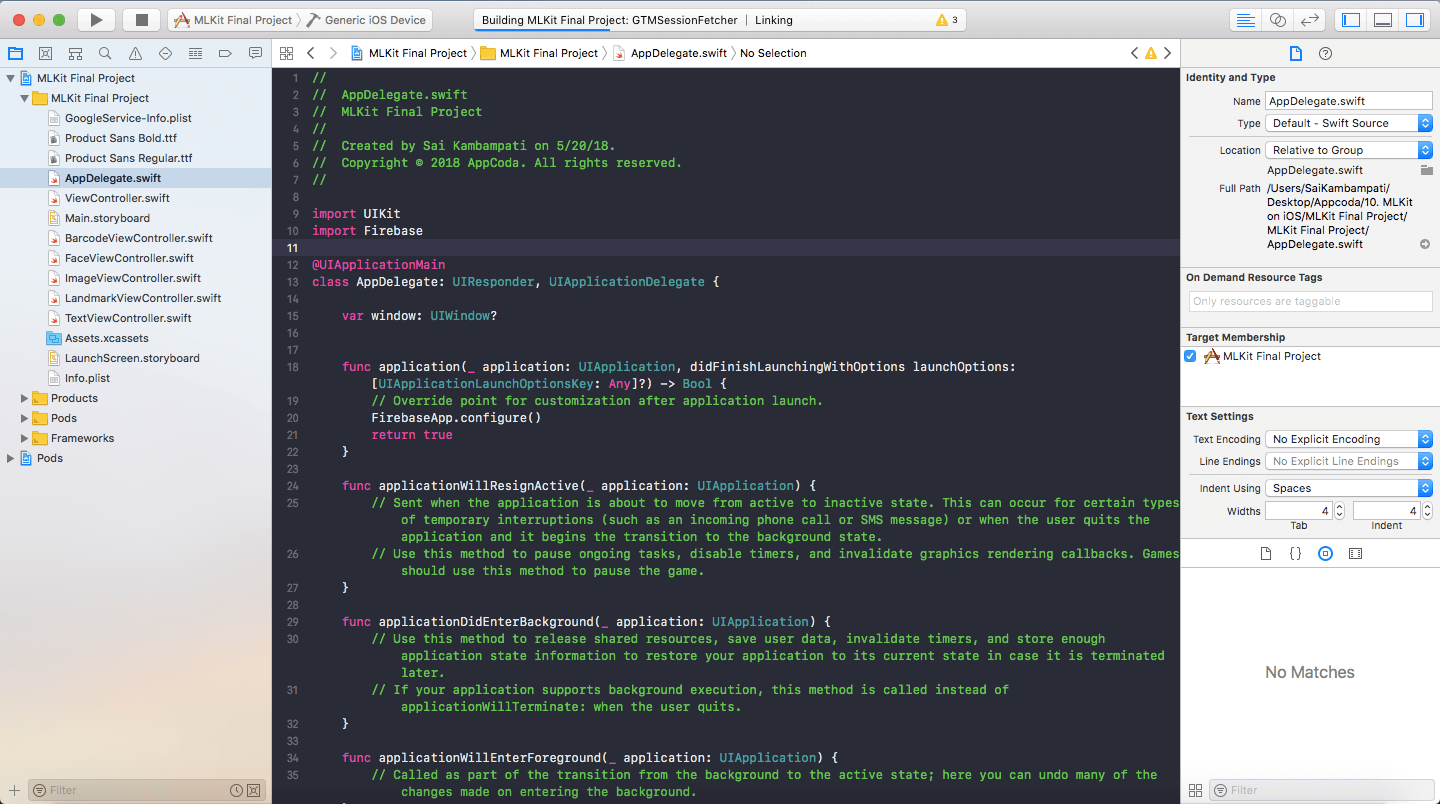
如果还有错误,打开项目的 Build Settings 栏,然后搜索 Bitcode 。你将会在 Build Options 下面看到一个 Enable Bitcode 的选项,把它设置成 NO ,重新构建。你现在应该会成功!
在 Firebase 控制台上点击 NEXT 按钮,进入第5步。现在,你所需要做的事情就是在一个设备上运行你的 app ,第5步将会被自动完成。然后你将会被重定向回到项目概览页面,现在这里会向你展示一些数据。
恭喜!你已经完成了本教程中最富有挑战的部分,剩下的就是用 Swift 添加 ML Kit 代码。现在是休息的最佳时机,但从现在开始,它只是在我们熟悉的代码中平稳的运行!
条码扫描
第一个实现的将是条码扫描,这个添加到你的 app 中是真的很简单。前往 BarcodeViewController ,你将会看到 Choose Image 按钮被点击时要做的事情的代码。为了访问所有 ML Kit 的协议,我们不得不导入 Firebase 。
import UIKit
import Firebase
接下来,我们定义一些将会在条码扫描函数中用到的变量。
let options = VisionBarcodeDetectorOptions(formats: .all)
lazy var vision = Vision.vision()
options 变量告诉 BarcodeDetector 将要识别的条码类型。 ML Kit 可以识别大部分常见格式的条码,比如:Codabar 、39 码、93 码、UPC-A 、 UPC-E 、 Aztec 、 PDF417 、 二维码等等。 出于我们的目的,我们将要求检测器识别所有格式类型。 vision 变量返回了一个 Firebase Vision 服务的实例,通过这个变量,我们可以执行大部分的计算。
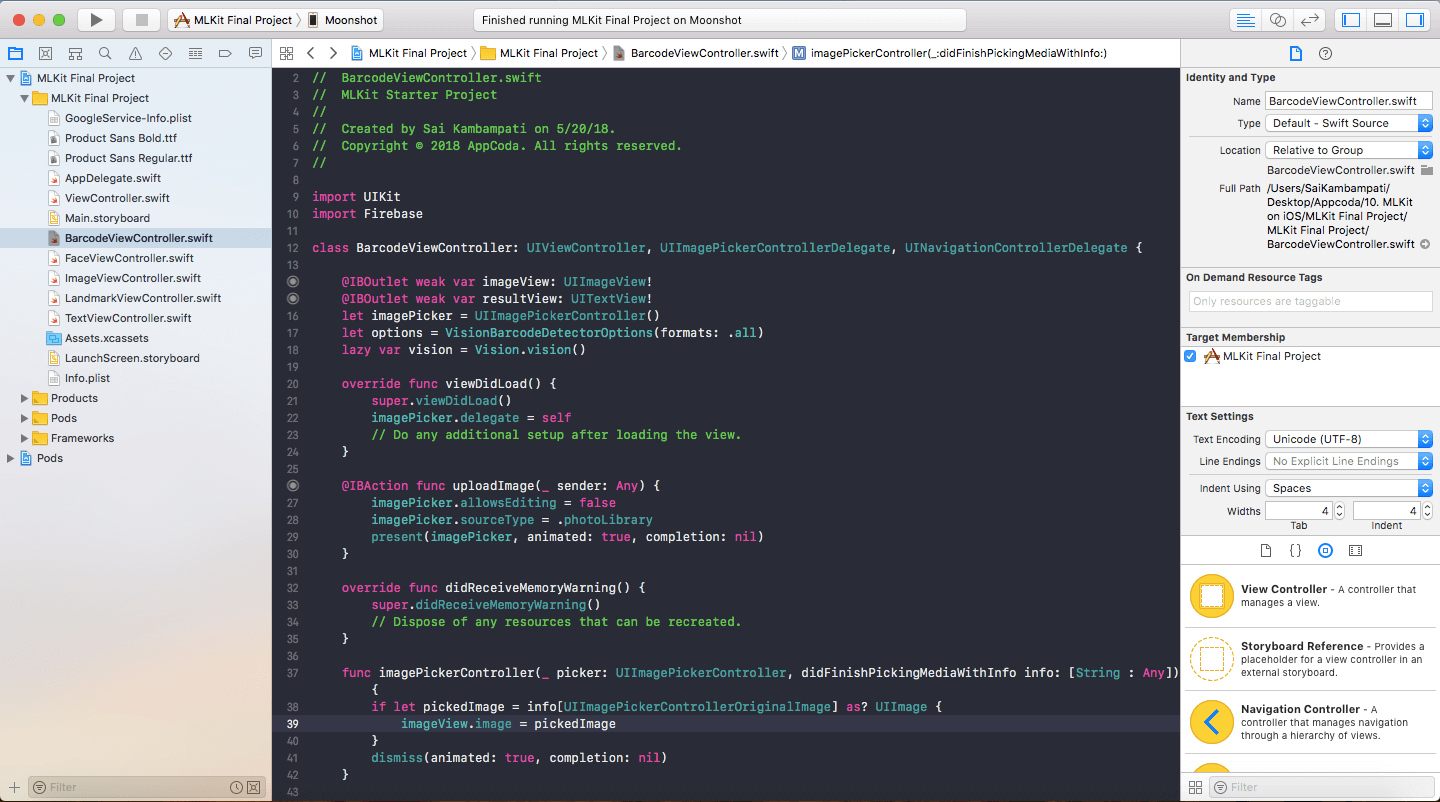
接下来,我们需要去处理识别逻辑,我们将会在 imagePickerController:didFinishPickingMediaWithInfo 函数中实现这些。当我们选择一张图片的时候这个函数会被调用。现在,这个函数只是把 imageView 设置成了我们选择的图片,在 imageView.image = pickedImage 下面一行添加一下代码。
// 1
let barcodeDetector = vision.barcodeDetector(options: options)
let visionImage = VisionImage(image: pickedImage)
//2
barcodeDetector.detect(in: visionImage) { (barcodes, error) in
//3
guard error == nil, let barcodes = barcodes, !barcodes.isEmpty else {
self.dismiss(animated: true, completion: nil)
self.resultView.text = "No Barcode Detected"
return
}
//4
for barcode in barcodes {
let rawValue = barcode.rawValue!
let valueType = barcode.valueType
//5
switch valueType {
case .URL:
self.resultView.text = "URL: \(rawValue)"
case .phone:
self.resultView.text = "Phone number: \(rawValue)"
default:
self.resultView.text = rawValue
}
}
}
这里有一些关于所做事情的快速概述。这些看起来很多其实很简单,这将是我们为本教程剩余部分所做的事情的基本格式。
- 首先就是定义两个变量:
barcodeDetector是 Firebase Vision 服务的条码检测对象,我们把它设置成可以检测所有条码类型。然后,我们定义一个和我们选择的图片的类型相同的图片叫做visionImage。 - 我们调用
barcodeDetector的detect方法,传入visionImage变量。我们定义了两个对象:barcodes和error。 - 首先,我们处理错误。如果有一个错误或者没有条码被识别到,我们就弹回 Image Picker View Controller 并把
resultView设置成「没检测到条码」。然后我们在函数中调用return因此函数中剩余的部分就不会被执行。 - 如果有一个条码被检测到了,我们使用 for 循环在每个识别到的条码中执行相同的代码。我们定义了两个常量:
rawValue和valueType。条码的原始值包含了它持有的数据,可能是文本、数字、图片等。条码的值类型表面它是什么类型的信息:邮件、联系方式、链接等。 - 现在,我们可以简单的打印原始值,但这不会有很好的用户体验。相反,我们将根据值类型提供自定义消息,我们检查它的类型,并根据它的类型在
resultView上设置一些文本。比如,如果是 URL ,我们会在resultView上设置文本为 「URL:」 和 显示 URL 内容。
编译和运行 app 。可能会非常地快!因为 resultView 是一个 UITextView 类型,因此你可以选择任何检测到的数据和它交互,比如数字、链接和邮件,这是非常的酷!
面容识别
接下来,我们将讨论一下面容识别。让我们更进一步,看看我们如何报告一个人是否在微笑,是否睁开眼睛等等,而不只是在脸上画个框。
和之前一样,我们需要在开始之前定义一些常量。
import UIKit
import Firebase
...
let options = VisionFaceDetectorOptions()
lazy var vision = Vision.vision()
这里和之前唯一的不同就是我们调用了默认的 FaceDetectorOptions 。我们在类的 viewDidLoad 方法中配置的这些选项。
override func viewDidLoad() {
super.viewDidLoad()
imagePicker.delegate = self
// 在视图加载后做的额外的事情
options.modeType = .accurate
options.landmarkType = .all
options.classificationType = .all
options.minFaceSize = CGFloat(0.1)
}
在 viewDidLoad 中我们定义了检测器的特性。首先,我们选择了使用的模式,有两个模式:精度和速度。因为这只是一个示例 app ,我们将使用精度模式,但在一些情况中速度更重要, options.modeType = .fast 这样调用可能更聪明。
接下来我们要求检测器去找出所有的地标和分类。这二者有什么不用?地标是面部的一个确定部分,比如右脸颊、左脸颊、鼻子底部、眉毛等等!分类有点像要检测的事件。当前, ML Kit Vision 只可以识别左/右眼是否睁开,人们是否在微笑。为了我们的目的,我们将处理分类会的事情(微笑和睁眼)。
我们设置的最后一个选项是最小化面部大小。当我们设置 options.minFaceSize = CGFloat(0.1) 的时候,我们正在要求期待面部大小的最小值。尺寸是表示头部宽度与图像宽度的比例。值为0.1要求检测器搜索最小面部,该面部大约是被搜索图像宽度的 10% 。
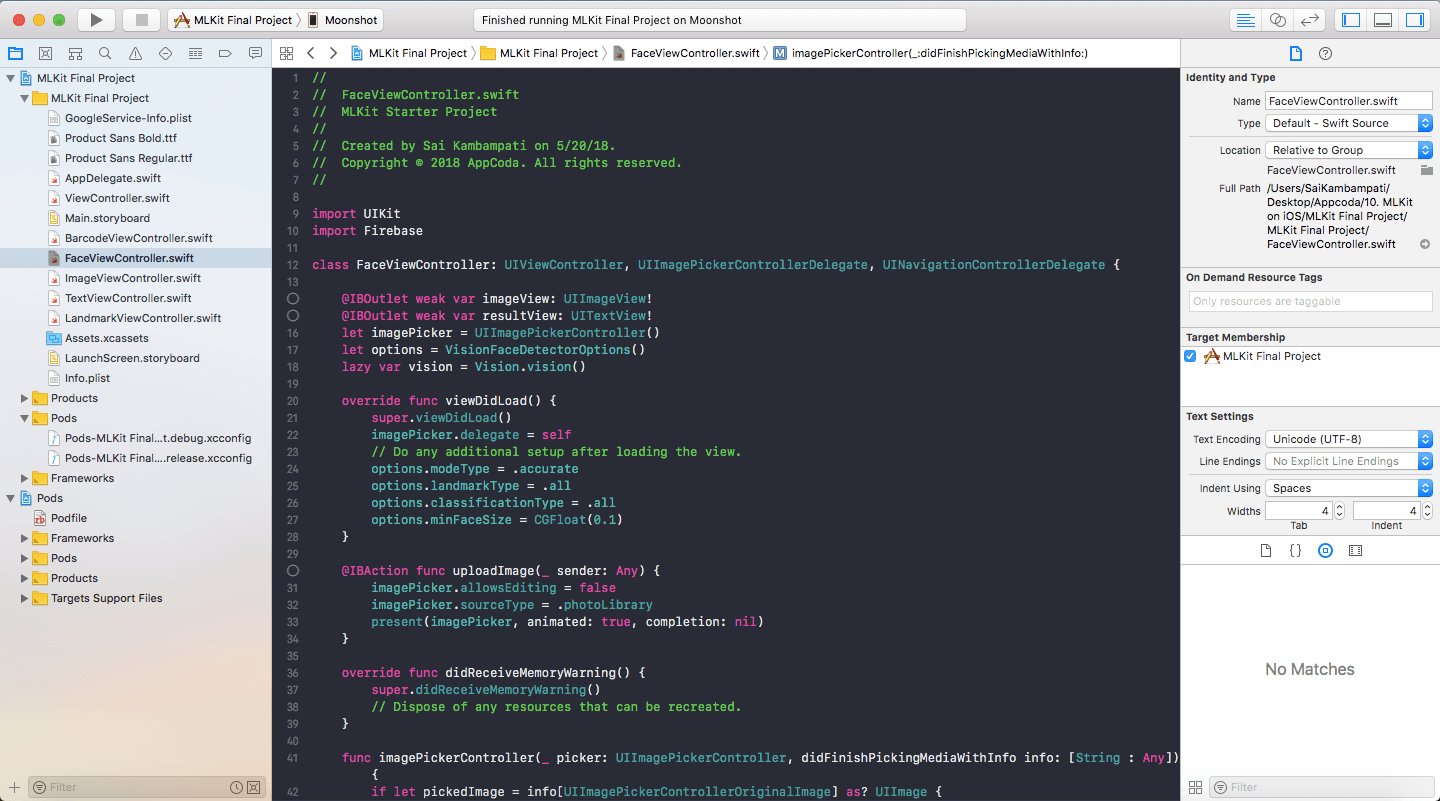
接下来,我们处理 imagePickerController:didFinishPickingMediaWithInfo 方法中的逻辑,在 imageView.image = pickedImage 下面,输入以下代码:
let faceDetector = vision.faceDetector(options: options)
let visionImage = VisionImage(image: pickedImage)
self.resultView.text = ""
这只是把 ML Kit Vision 服务根据我们之前配置的选项设置成一个面容检测器。我们也定义了一个 visionImage 去显示我们选择的那个图片。由于我们已经运行了好几次了,我们想要清空 resultView 因此我们在第三行清空它。接下来,我们调用 faceDetector 的检测函数。
//1
faceDetector.detect(in: visionImage) { (faces, error) in
//2
guard error == nil, let faces = faces, !faces.isEmpty else {
self.dismiss(animated: true, completion: nil)
self.resultView.text = "No Face Detected"
return
}
//3
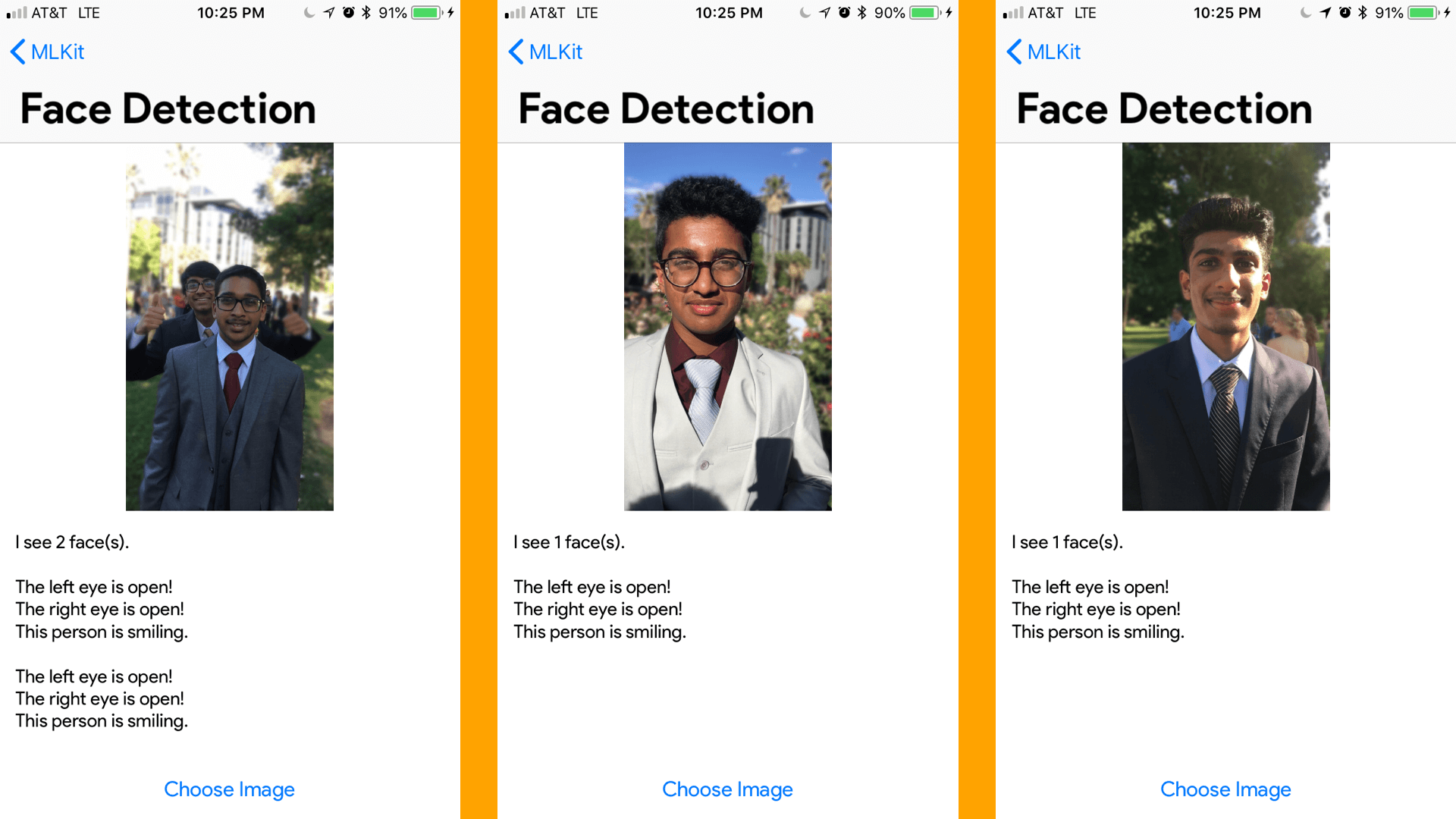
self.resultView.text = self.resultView.text + "I see \(faces.count) face(s).\n\n"
for face in faces {
//4
if face.hasLeftEyeOpenProbability {
if face.leftEyeOpenProbability < 0.4 {
self.resultView.text = self.resultView.text + "The left eye is not open!\n"
} else {
self.resultView.text = self.resultView.text + "The left eye is open!\n"
}
}
if face.hasRightEyeOpenProbability {
if face.rightEyeOpenProbability < 0.4 {
self.resultView.text = self.resultView.text + "The right eye is not open!\n"
} else {
self.resultView.text = self.resultView.text + "The right eye is open!\n"
}
}
//5
if face.hasSmilingProbability {
if face.smilingProbability < 0.3 {
self.resultView.text = self.resultView.text + "This person is not smiling.\n\n"
} else {
self.resultView.text = self.resultView.text + "This person is smiling.\n\n"
}
}
}
}
这和我们之前在条码检测函数中写的非常相似。下面是发生的一切:
- 我们在
visionImage上调用detect函数来寻找faces和errors. - 万一有错误或者没有面容,我们把
resultView的文本设置为「没有检测到面容」,并退出函数。 - 如果面容被检测到了,我们第一个表达式是在
resultView上打印出我们看到的面容的数量。你将会在本篇教程中的很多字符串里发现\n,这标志着空行。 - 然后我们深入讨论细节。如果
face对左眼睁开有一个概率,我们就检查看一下这个概率是多少。在本例中,我已经设置了,如果概率小于 0.4 左眼就是闭着的。你可以用同样的方式去设置右眼,你可以修改成你想的值。 - 同样的,我会检查微笑概率,如果小于 0.3 这个人就很可能没有笑,否则面容就是微笑的。
注意: 我选择的这些值是基于我感觉可能是识别出来的最好的值。由于微笑比睁眼更难去检测,我降低了它的概率值,因此猜对它的可能性更高。
编译和运行 app ,看看它如何执行的!随意调试这些值并玩转他们!
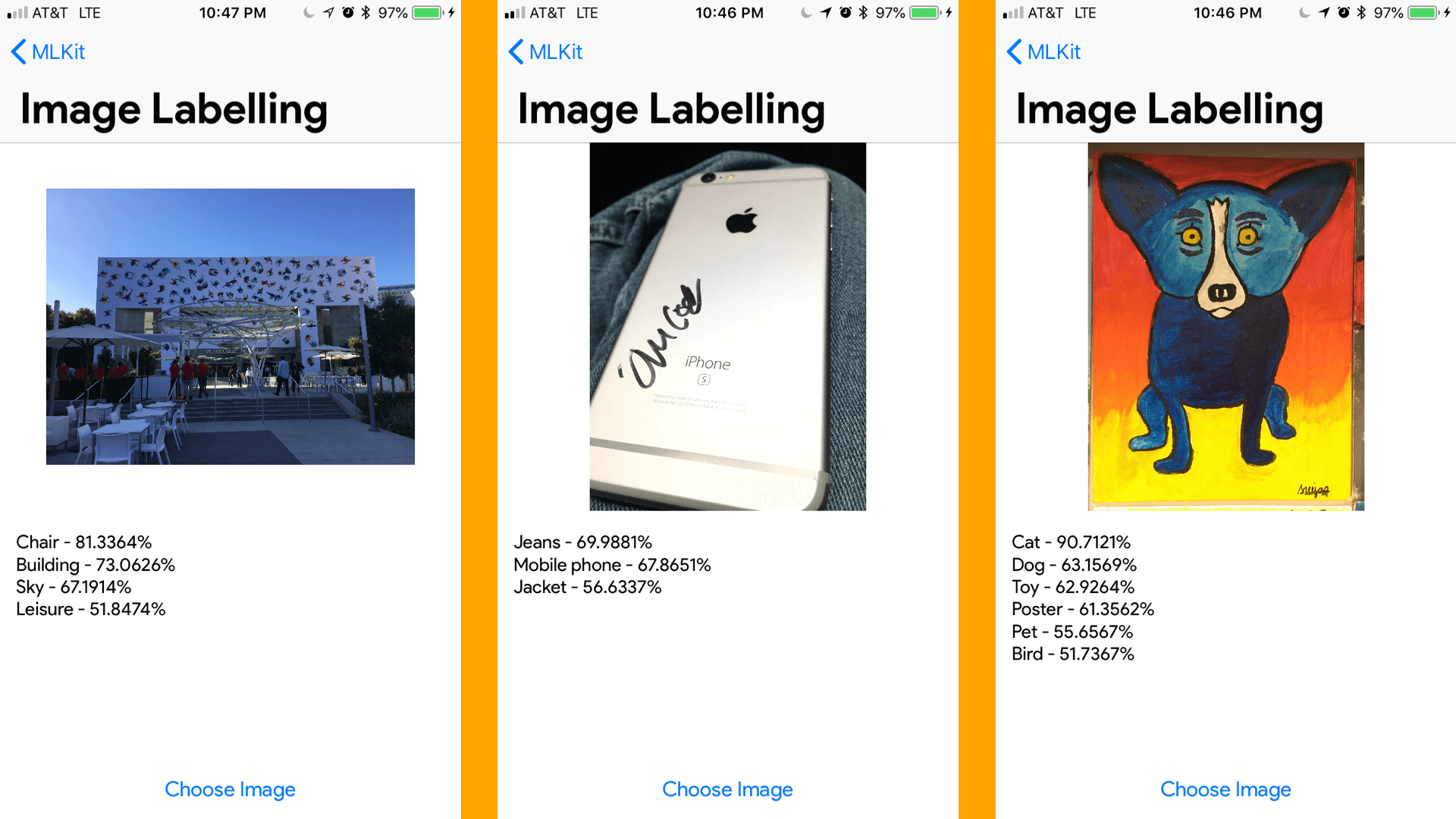
图像标签
接下来,我们将开始图像标签。这比面容检测简单多了。实际上,你有图像标签和文本识别两个选项。你可以在设备上完成机器学习(这是 Apple 更喜欢的,因为所有数据都属于用户,可以离线运行,不需要调用 Firebase ),或者用 Google 的 Cloud Vision,这里的优势是模型将会被自动更新并且有更高的精确度,有一个更大的,精确的模型大小在云中比设备中更容易。然而,我们将继续到目前为止所做的一切,并只实现设备版本。
看看你是否能自己实现它!它和前面两个场景非常相似。如果不行,也行!这就是我们应该做的!
import UIKit
import Firebase
...
lazy var vision = Vision.vision()
不像之前,对于标签检测我们将使用默认设置,因此我们只需要定义一个常量。其它事情就和之前的一样,将在 imagePickerController:didFinishPickingMediaWithInfo 函数中, imageView.image = pickedImage 的下面添加几行代码:
//1
let labelDetector = vision.labelDetector()
let visionImage = VisionImage(image: pickedImage)
self.resultView.text = ""
//2
labelDetector.detect(in: visionImage) { (labels, error) in
//3
guard error == nil, let labels = labels, !labels.isEmpty else {
self.resultView.text = "Could not label this image"
self.dismiss(animated: true, completion: nil)
return
}
//4
for label in labels {
self.resultView.text = self.resultView.text + "\(label.label) - \(label.confidence * 100.0)%\n"
}
}
这应该开始看起来很熟悉了。让我简要回顾一下:
- 我们定义了
labelDetector告诉 ML Kit 的 Vision 服务去从图片中识别标签。我们定义了visionImage成为我们选择的图片,我们情空resultView防止多次调用这个函数。 - 我们在
visionImage上调用detect函数去找出labels和errors。 - 如果有一个错误或者没能够标记图像,我们就退出函数告诉用户我们不能够标记图像。
- 如果一切都好了,我们设置
resultView文本为图片的标签,以及 ML Kit 对那个图像的标签有多大的信心。
很简单,对不对?编译并运行你的代码!看看标签有多准确(或者疯狂)呢?
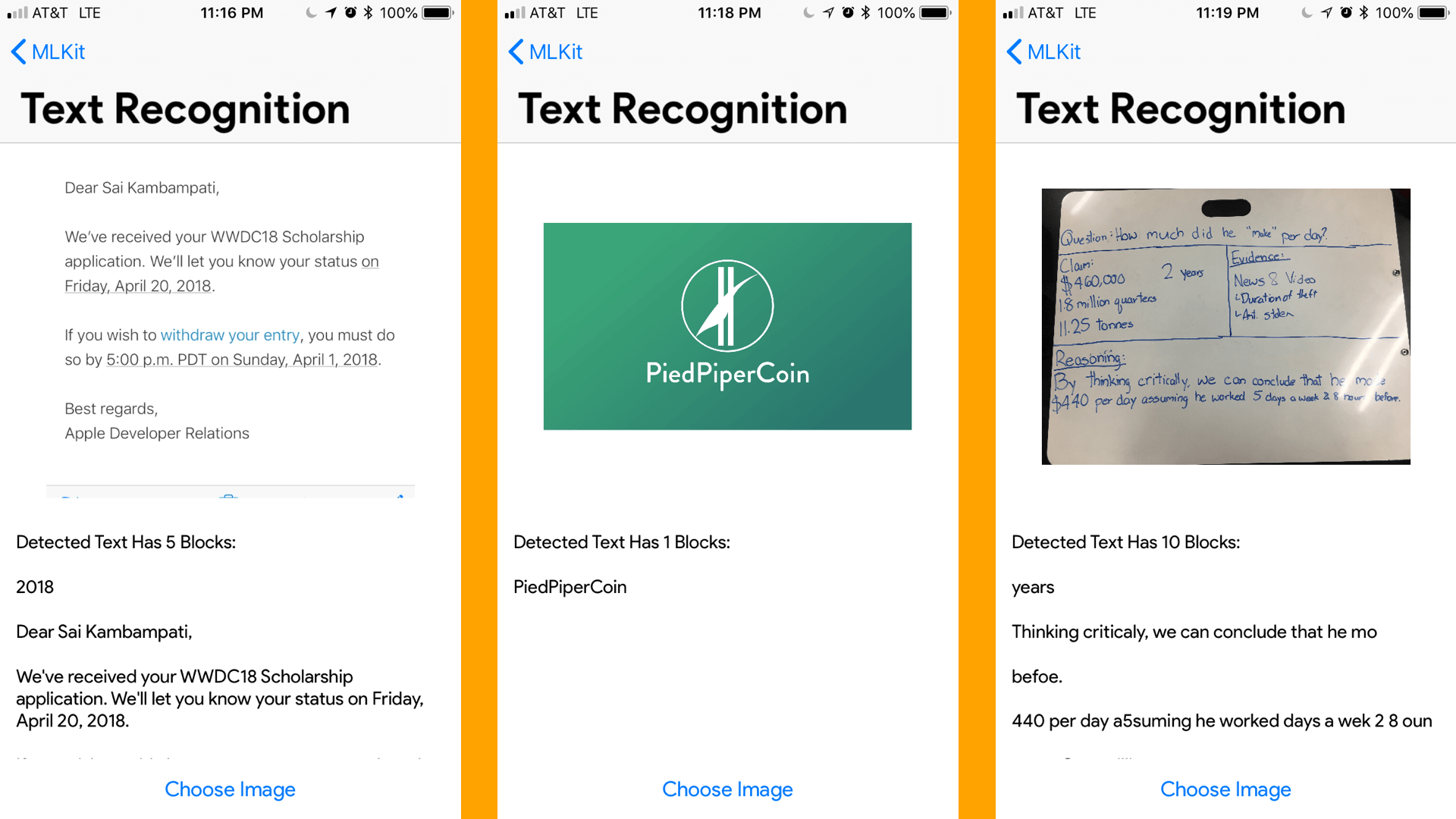
文本识别
我们几乎都做完了!光学字符识别,或者叫 ORC ,这两年就移动应用而言变得非常地流行。使用 ML Kit ,在你的 apps 中去实现这个会更简单。让我们看看如何实现吧!
同样的,文本识别可以被连接到 Google 云,并可以像图像便签那样调用云中的模型,但我们现在将使用设备中的 API 。
import UIKit
import Firebase
...
lazy var vision = Vision.vision()
var textDetector: VisionTextDetector?
和之前一样,我们调用 Vision 服务并定义一个 textDetector 。在 viewDidLoad 方法中,我们可以把 vision 的文本检测器设置给 textDetector 变量。
override func viewDidLoad() {
super.viewDidLoad()
imagePicker.delegate = self
textDetector = vision.textDetector()
}
接下来,我们只在 imagePickerController:didFinishPickingMediaWithInfo 中处理所有的事情。照常,我们将在 imageView.image = pickedImage 下面输入逻辑。
//1
let visionImage = VisionImage(image: pickedImage)
textDetector?.detect(in: visionImage, completion: { (features, error) in
//2
guard error == nil, let features = features, !features.isEmpty else {
self.resultView.text = "Could not recognize any text"
self.dismiss(animated: true, completion: nil)
return
}
//3
self.resultView.text = "Detected Text Has \(features.count) Blocks:\n\n"
for block in features {
//4
self.resultView.text = self.resultView.text + "\(block.text)\n\n"
}
})
- 我们把
visionImage设置成选择的图片,我们在这张图片上运行detect函数去查找features和errors。 - 如果有一个错误或没有文本,我们告诉用户「没有识别任何文本」并退出函数。
- 第一段信息是我们将告诉我们用户的是已经检测到了多少个文本块。
- 最后,我们将
resultView的文本设置为每个块的文本,在\n \n之间留出一个空格(2个新行)。
测试一下!尝试输入不同字体和颜色的文本,我的结果表明,在打印的文本上表现完美,但在手写文本上还有很艰难。
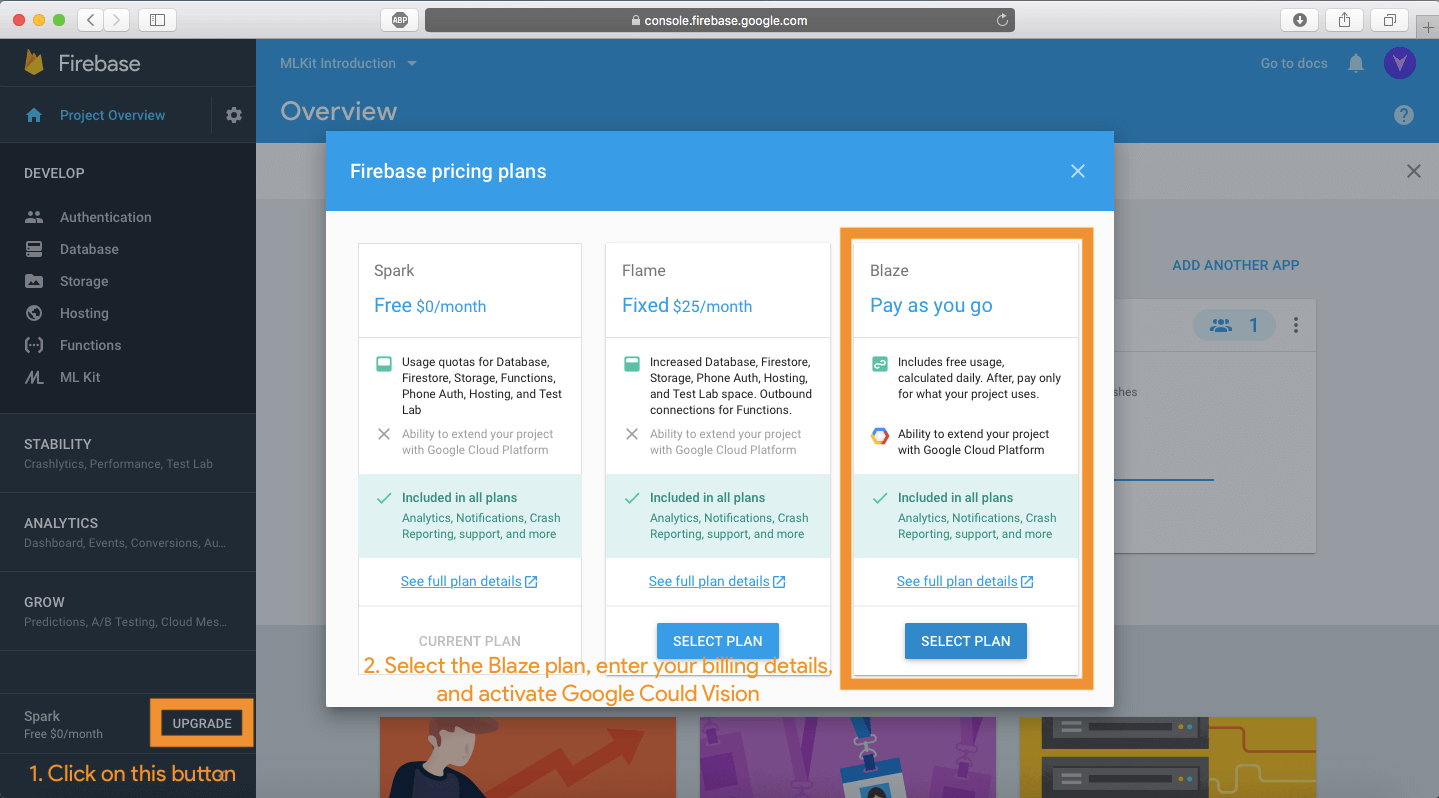
地标识别
现在,地标识别可以像其它4类一样被实现。不幸的是,ML Kit 到目前为止不支持设备上的地标识别。要执行地标识别,您需要将项目计划更改为 「Blaze」并激活Google Cloud Vision API。
然而,这已经超出本教程的范围了,如果你觉得你可以接受挑战,你可以在这里找到文档并实现代码。最终的项目中也会包含这个代码。
结语
这真的是一个大教程,所以请随时向上回滚,复习一下你可能不理解的地方。如果仍然有问题无法解答,请在下方评论。使用 ML Kit ,你已经看到它是如此地简单,就能把在你的 app 中实现一个聪明的机器学习功能。可以创建的应用程序的范围很大,所以这里有一些想法供你试用:
- 给视觉障碍者做一个识别文本并读给用户听的 app 。
- 面容追踪的 app ,比如 Try Not to Smile by Roland Horvath
- 条码扫描
- 基于标签搜索图片
能性是无穷无尽的,它都基于你可以想象的以及你希望如何帮助你的用户。在这里可以下载最终的项目,通过查看他们的文档你可以更多关于 ML Kit 的 API 。希望你在本教程中学到了一些新的东西。在下面评论中,让我知道它是如何进行的。
对于完整的项目,你可以在 GitHub 上查看。