本文是翻译于AppCoda社区,如有版权问题,请告知,会配合处理
Core ML 是苹果的机器学习框架。一年以前发布的, Core ML 提供了一种只需要几行代码,就可以将强大和智能的机器学习能力集成到应用中的方法。今年,在 WWDC2018 ,苹果发布了 Core ML 2.0 —— Core ML 的下一版本都是围绕着优化模型大小、提高性能和开发者能够指定他们自己的 Core ML 模型来优化流程。
在本文中,我将向你介绍 Core ML 2.0 的所有新特性,以及如何将其应有到你的机器学习应有程序中!如果你是 Core ML 的新手,我推荐你通过这篇文章去熟悉 Core ML 。如果熟悉 Core ML,那我们就开始了。
注意:为了尝试这些技术,你需要在你的电脑上安装 macOS Mojave,也需要安装 coremltools 测试版。如果没有,不用担心,在后面我会说明如何下载。
快速回顾
在 App Store 有很多可以执行强大任务能力的优秀 app 。比如,你可以找到一个文字理解的 app,或者是根据设备运动就知道你在做什么运动的 app ;更有甚者,有些 app 会根据先前的图片对图片进行过滤。这些 app 都有一个共同点:他们都是使用机器学习的例子,所有这些都可以用 Core ML 模型创建。
Core ML 使开发者把机器学习模型集成到他们的 app 变得简单,你可以创建一个理解对话上下文和识别不同语音的 app 。此外,苹果已经使开发者可以通过 Vision 和 Natural Language 这两个框架进行实时图像分析和自然语言理解。
使用 VNCoreMLRequest API 和 NLModel API,你可以加大提高 app 的 ML 能力,因为 Vision 和 Natural Language 是建立在 Core ML 之上的!
今年,苹果主要专注于三个要点,去帮助 Core ML 开发者。
- 模型大小
- 模型性能
- 自定义模型
让我们一起探索这3点吧!
模型大小
Core ML 的一个巨大优点就是所有事情都是在设备上完成的。这就确保了用户的隐私安全并且计算可以在任何地方进行。然而,随着更高精度的机器学习模型被使用,它们有着很大的体积。把这些模型导入到你的 app 中会占用用户设备的大量空间。
苹果决定给他们的开发者一个工具,去量化他们的 Core ML 模型。量化模型是指使用更紧凑的形式去存储和计算数字的技术。在任何机器学习模型的根的核心,就是一个试图计算数字的机器。如果我们可以减少数字或者以一种占用空间更少的形式去存储它们,我们就可以大幅度的减少模型的大小。这可以减少运行时内存的使用和获得更快的计算。
对于一个机器学习模型有三个主要的部分:
- 模型数量
- 权重数量
- 权重大小
当我们量化一个模型的时候,会减少权重大小!在 iOS 11 中, Core ML 是被存储在一个 32 位的模型中,随着 iOS 12 到来,苹果给我们在 16 位甚至 8位模型中存储模型的能力!这就是本文将会看到的内容!
如果你不知道什么是权重,这有一个很好的类比。好比,你打算从你家去超时,第一次,你可以走一条特定的路线;第二次,你会尝试找一条短点的路线去超市,因为你已经知道了去超市的路了;而第三次,你将会采取更短的路线,因为你已经知道了前面的两条路了。随着时间的推移,你每次去市场都会学到更短的路径。这种该走哪条路的知识被称为权重。因此,最精确的路径就是权重最大的路径。(译者注:以结果为导向,权重越大结果越精确)
让我们开始实践它,开始编码!
权重量化
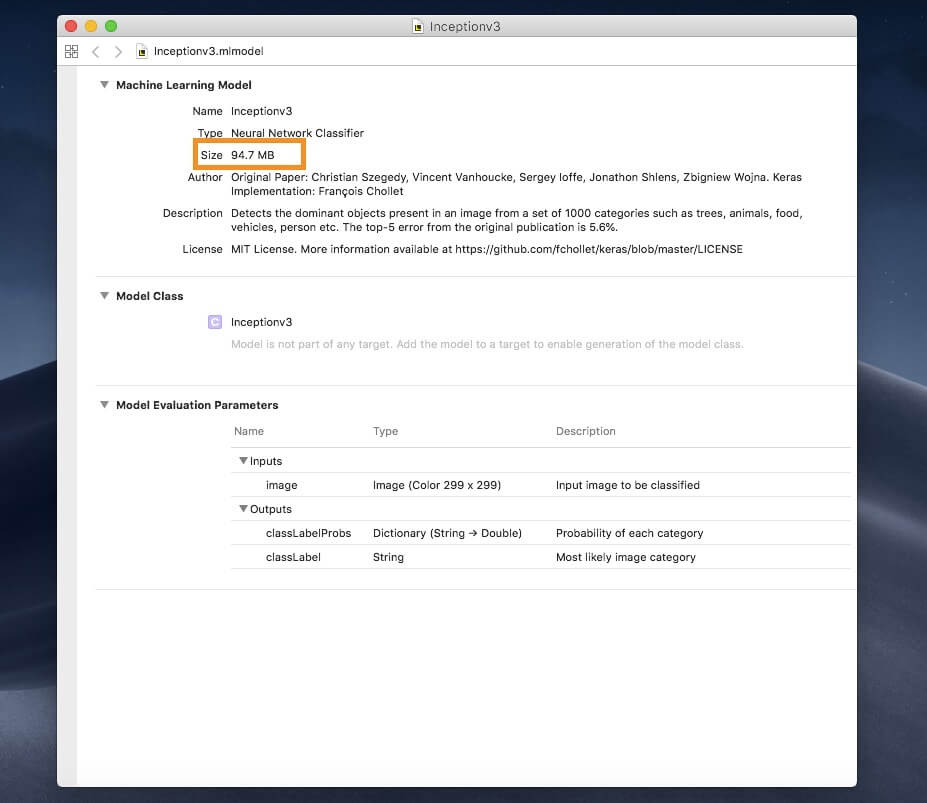
作为示例,我们在 demo 中使用一个流行的机器学习模型叫做 Inception v3 。你可以在这里下载它的 Core ML 格式的模型。
打开这个模型,你可以看到它占用了 94.7 MB 的空间。
我们将使用 Python 包的 coremltools 去量化这个模型。让我们看看如何量化吧!
如果你的设备中没有安装 python 或者 pip ,你可以在这里学习安装方法
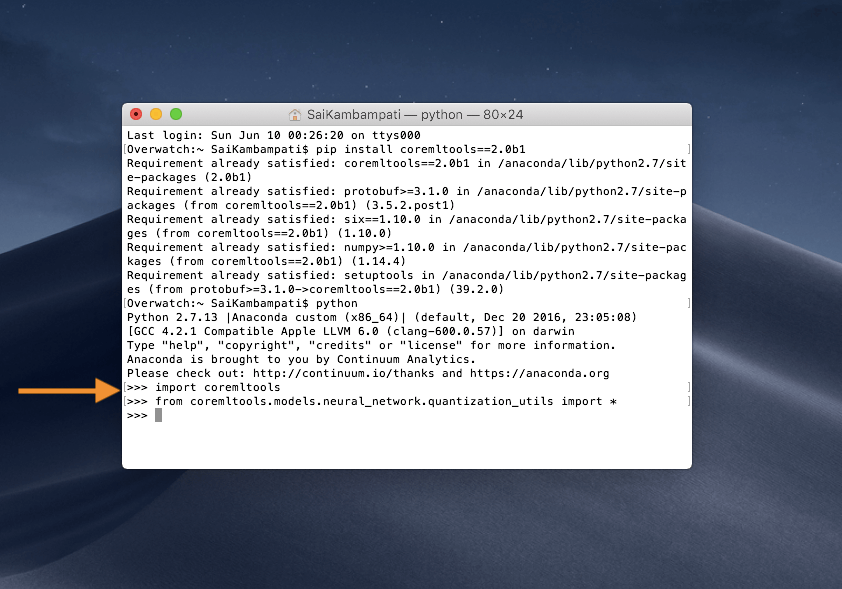
首先,你需要确保已经安装了 coremltools 的测试版,打开终端,然后输入下面的代码:
pip install coremltools==2.0b1
你应该看到一个像这样的输入。

这个命令成功安装了 Core ML Tools beta 1 的测试版。接下来几步需要一些 Python 代码。然而不用担心,都会很简单并不需要很多代码!打开你选择的 Python 编辑器或者跟着终端走。首先让我们导入 coremltools 包,在终端中输入 python 然后当编辑器出现后输入下面的代码:
import coremltools
from coremltools.models.neural_network.quantization_utils import *
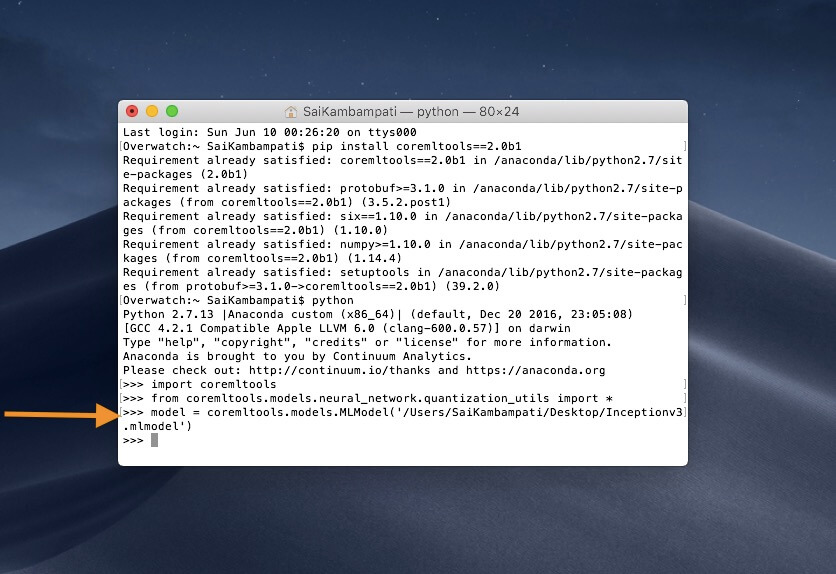
这是导入 Core ML 工具包和所有量化工具;接着,我们定义一个 model 变量,把它的 URL 设置为刚刚下载的 Inceptionv3.mlmodel 所在路径。
model = coremltools.models.MLModel('/PATH/TO/Inceptionv3.mlmodel')
在我们量化模型之前(只需要 2 行代码!),我来给你介绍一点神经网络的背景知识。
一个神经网络是由不同的层组成,这些层只不过是一个有许多参数的数学函数,而这些参数就称为权重。
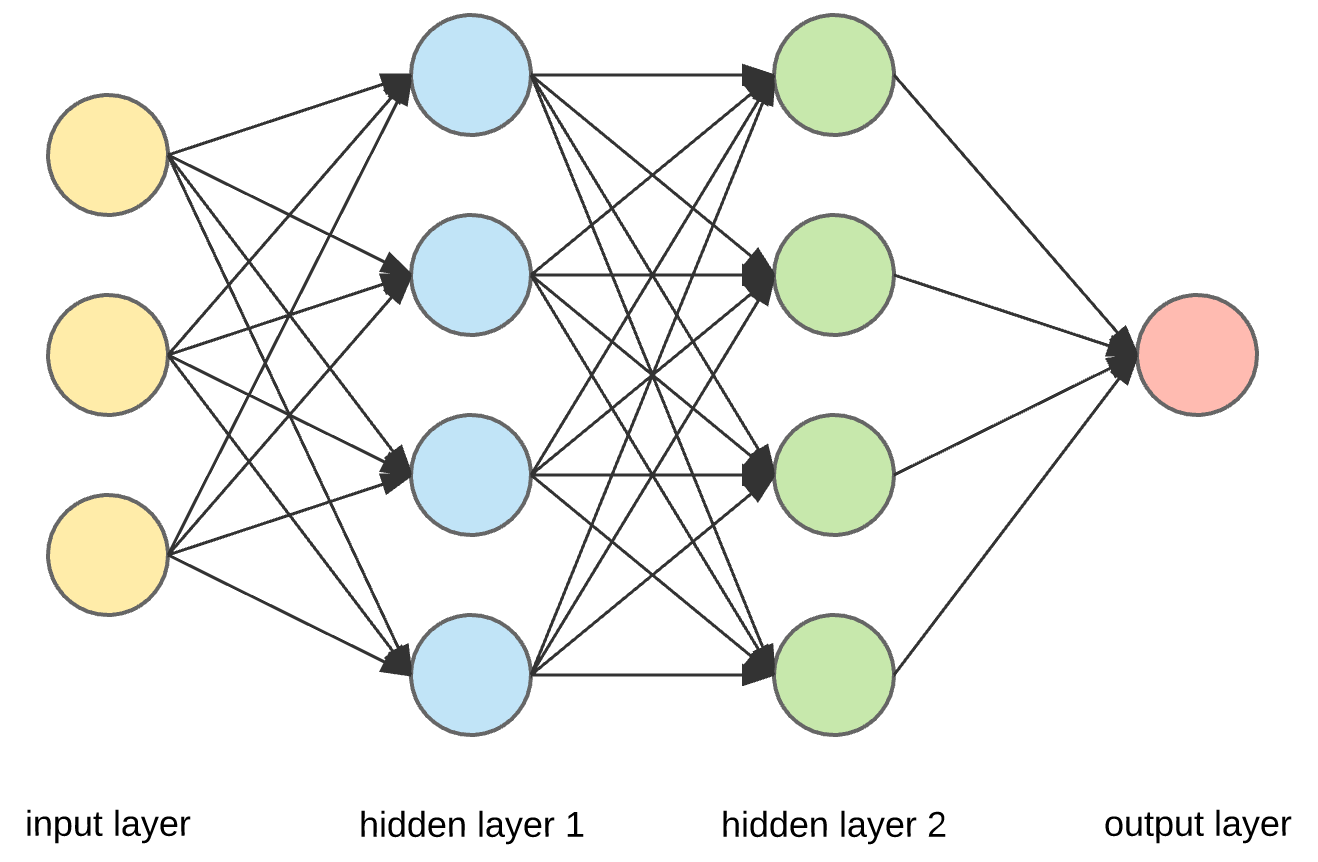
当我们量化权重是,会取一个最小权重值和一个最大权重值,然后映射他们。有很多中方式去映射它们,但最常用的就是线性和查询。线性量化是指均匀的映射权重并减少它们。在查询表量化中,该模型会构建一个表,并基于相似度对权重进行分组,然后将其减少。
如果这样听起来有点复杂,不用担心。我们所需要做的就是选择我们想要模型被表示的位数以及要选择的算法。首先,让我们看看如果我们选择线性量化模型会发生什么。
lin_quant_model = quantize_weights(model, 16, "linear")
在上面的代码中,我们使用线性量化把 Inceptionv3 模型的权重量化到 16 位。运行代码,你会看到一个长长的列表,显示正在量化的每一层。

我们保存这个模型,看看和原模型相比会怎样。选择一个保存的路径然后输入下面的代码。
lin_quant_model.save('Path/To/Save/QuantizedInceptionv3.mlmodel')
现在打开两个模型,然后比较一下大小。
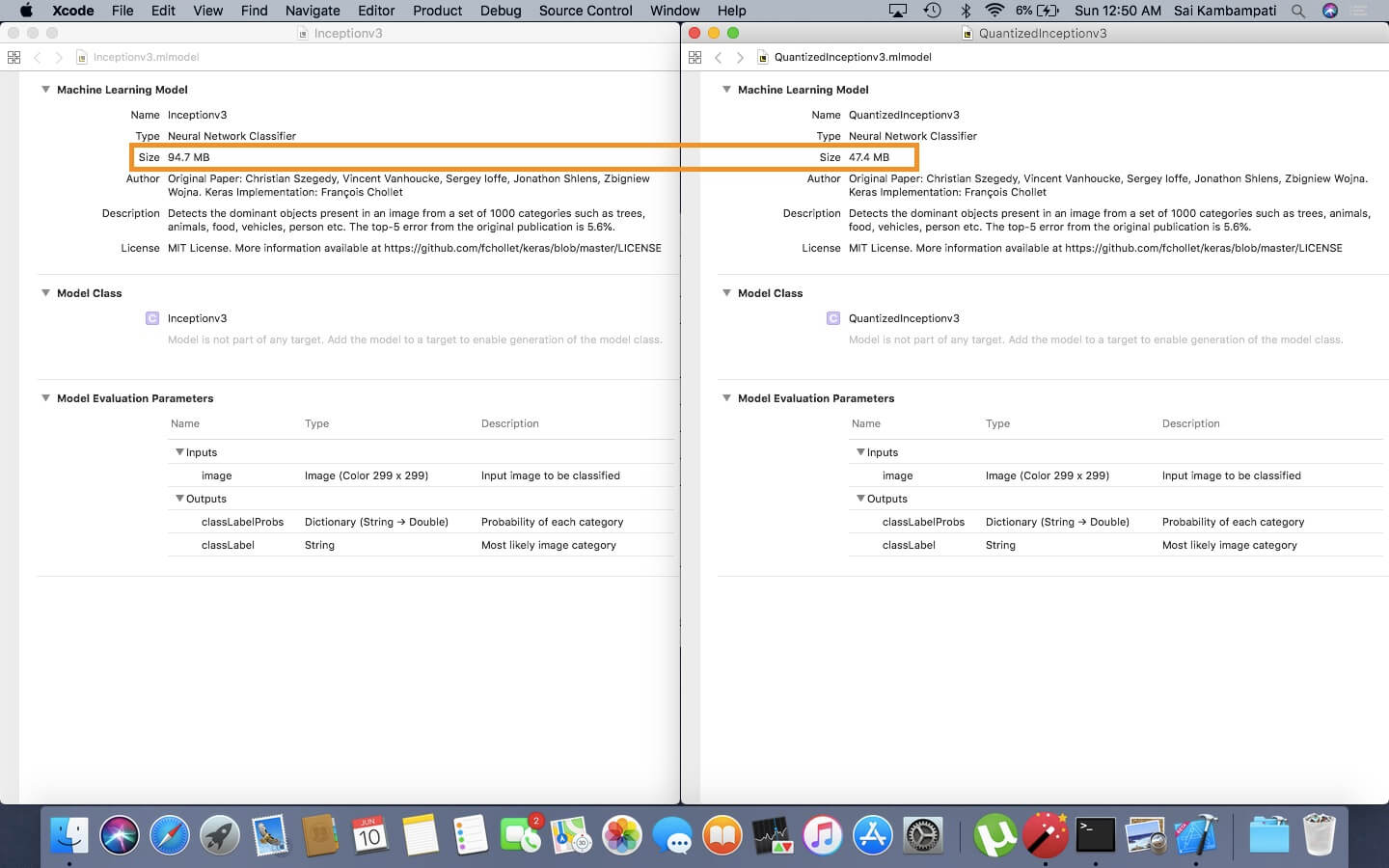
当我们用 16 格式来展示 Inceptionv3 模型,它会占用更少的空间!
然后,记住什么是权重量化才是最重要的。
上文在我的类比中,我说过权重越大结果越精确。当我在量化模型时,随便大小的减小我们也在降低模型的精确度。量化是精确度折衷。量化模型是对权重大小的近似,所以运行你的量化模型并观察它们的表现总是很重要的。
理想情况下,我们想量化我们的模型,同时尽可能的保持高精度;这可以通过寻找正确的量化算法去实现。在前面的例子中,我们使用了线性量化;现在,让我尝试一个查询量化会有怎样的表现。和之前一样,在终端中输入以下代码:
lut_quant_model = quantize_weights(model, 16, "kmeans")

当这个模型量化完成后,我们需要通过运行一些示例数据,把 lin_quant_model、lut_quant_model 去和原模型进行比较。这样,我们就可以找到和原模型最相似的那个量化模型。在这下载示例图片。输入以下代码,然后看看哪个模型表现更好!
compare_models(model, lin_quant_model, '/Users/SaiKambampati/Desktop/SampleImages')
这个过程可能需要一点时间,但在两个模型都处理完成之后,你会得到如下所示的输出:
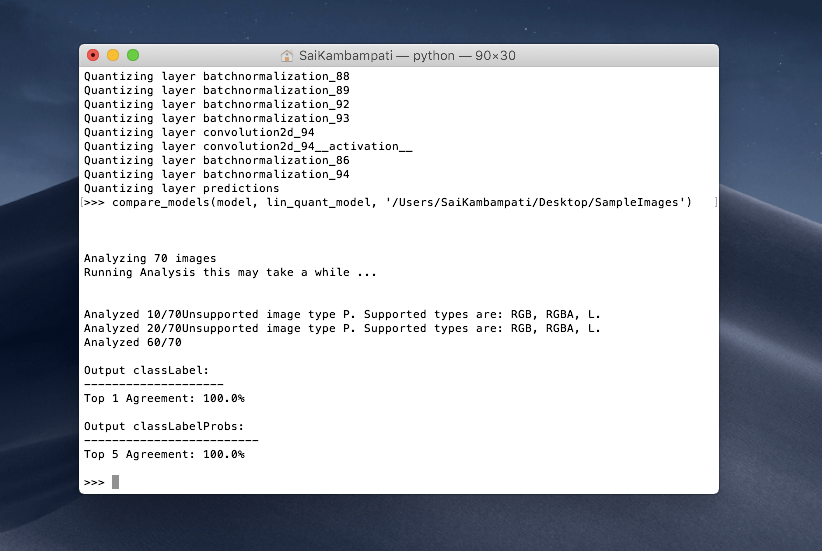
我们对 Top 1 Agreement 很感兴趣,它显示 100% ,意味着它和我们的模型 100% 匹配。这对我们来说非常棒,因为我们现在有着占用空间更小的量化模型,并且它有着和原模型近似相同的精确度!我们现在可以把这个模型导入到项目中了,如果我们想要,也可以比较一下查询表量化!
compare_models(model, lut_quant_model, '/Users/SaiKambampati/Desktop/SampleImages')
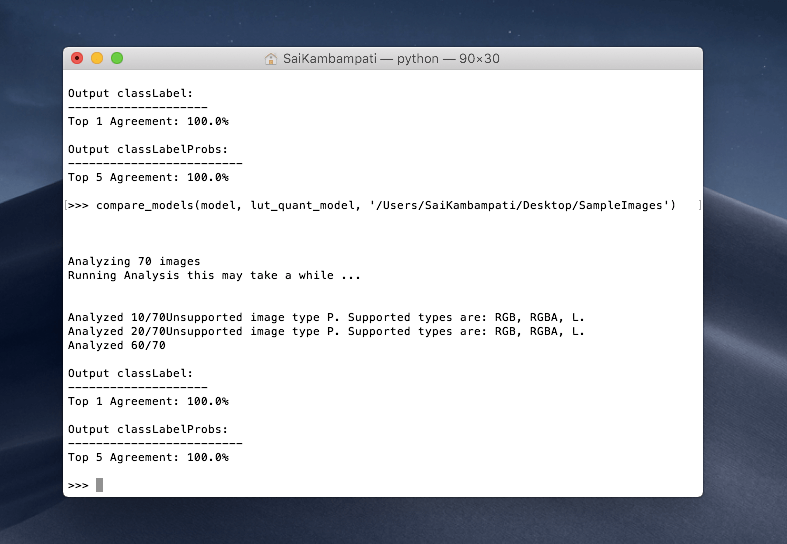
我们也得到了 100% 的输出,说明两个模型都是兼容的!我鼓励你尝试量化不同的模型。在上面的示例中,我们将 Inceptionv3 模型量化为 16 位。看看如果你继续把模型量化为 8 位表示,甚至量化到 4 位表示,并用示例数据进行比较!它会有怎么样的表现?

上面的图片描述了当我使用线性算法把 Inceptionv3 模型量化到 1 位表现是发生了什么。正如你所看到的,模型大大减小了,但精确度也降低了!事实上,它是完全错误的,精确度 0% 。试着用量子化来寻找快乐的媒介。一定要记得测试量化模型,以确保它们执行准确!
性能
苹果在 Core ML 2 中接下来关注的点就是性能。因为我们是在设备上运行 ML 计算,所以我们希望它能够快速、准确,这可能会非常复杂。幸运的是,苹果已经提供了一个方法去改善我们 Core ML 模型的性能。让我来感受一下示例。
风格转换是一种机器学习的应用,它基本上就是把一张特定的图片从一种风格转换成另一种风格。如果你以前用过 Prisma app ,下面就是使用风格转换的示例。
如果我们去调研风格转换的神经网络,我们就会发现这一点,这个算法有一组特定的输入,神经网络的每一层都会对原图增加一种特定的转换。这就意味模型必须接受每一个输入并将其映射到输出,并据此作出预测。这样的预测有助于建立权重。这在代码中会是什么样子呢?
// 遍历输入
for i in 0..< modelInputs.count {
modelOutputs[i] = model.prediction(from: modelInputs[i], options: options)
}
在上面这段代码中,你发现对于每个输入我们都会调用模型去生成一个预测,并基于一些 options 产生一个输出。然后,迭代每个输入都会花费很长时间。
为了战胜这个,苹果推出了一个新的批次 API!不像 for 循环,机器学习中的一个批次是当所有的输入被输入到模型中,而得到一个准确的预测。这会节省很多时间,重要的是代码会更少!
看一下用新的批次预测 API 编写一个 for-loop 的代码!
modelOutputs = model.prediction(from: modelInputs, options: options)
就这样,只需要一行代码就能搞定。你可能会思考,「等一下,我从来没有这么做过?这听起来有点复杂。我甚至都不知道在哪里用这个?」。这就把我带到了最后一点,自定义模型。
定制自己的模型
当你揭开神经网络的面纱,就会看到它是由很多层组成的。但是,当你试图把一个神经网络从 Tensorflow 转换到 Core ML,就可能会出现一些场景。或者可能出现在从 Keras 到 Core ML 的管道中。然后,可能会有这样的例子,在 Core ML 中根本没有能正确进行模型转换的工具!通过上述我想表达的意思是什么呢?让我们来看另一个例子。
图片识别模型是使用一个卷积神经网络( CNN )创建的。CNNs 是有一系列高度优化的层组成的。当你把神经网络从一个格式转换成 Core ML 时,你需要转换每一层。然后,可能会发生一些罕见的场景, Core ML 仅仅是没有提供这一层的转换工具。在过去,遇到这样的情况你什么也做不了,但在 iOS 12 中,苹果工程师介绍了 MLCustonLayer 协议,允许开发用 Swift 去创建他们自己的层。有了 MLCustomLayer ,你可以自己在 Core ML 模型中去定义神经网络的层的行为。然而,值得注意的是,自定义层只适用于神经网络模型。
如果你现在听着感觉非常复杂,不用担心,这通常需要熟练的数据科学家或者机器学习工程师才能理解神经网络的所有复杂之处,并有写出他们自己的模型的能力。这已经超出了本文的讨论范围,因此,我们不去深究它。
结语
以上就是 Core ML 2.0 新变化的总结。 Core ML 2.0 的目标是模型更小、更快、更多的可定制。我们已经看到了如何通过量化权重去减少 Core ML 模型的大小,通过新的批次 API 去提高模型的性能,并且示例了在哪里我们可能需要去写自定义的层。作为一个开发者,我预测(看看我做了什么)与其它两个技术(批次 API 和 自定义层)相比,你将会更多地使用权重量化。
如果你有兴趣深入探索 Core ML 2.0,这里有一些超棒的资料供你参考!